Регулярные выражения
Содержание:
- Задачки (пока без картинок)
- Unicode категории (category)¶
- PHP regex extracting matches
- Статичные регэкспы
- Символьные классы — \d \w \s и .
- Практические примеры сложных регулярных выражений
- str.replace(str|regexp, str|func)
- PHP PRCE functions
- Getting Started With Regular Expressions
- PHP regex alternation
- Бекслеши
- Escape-знаки
- Опечаточники
- Описание
- Метасимволы
- Строковые методы, поиск и замена
- Подстановки
- PHP regex subpatterns
- Built-in Regular expression Functions in PHP
- Parse Apache Logs
Задачки (пока без картинок)
- На вход скрипта дан введенный пользователем номер телефона в
виде 8-911-404-44-11 или +7(812)6786767 (в начале 8 или +7, потом идут 10 цифр и, возможно, какие-то символы).
То есть, как и в прошлой задаче, человек вводит номер как хочет.
Надо проверить номер на правильность и привести любой номер к единому формату 89114044411
(то есть, заменить +7 на 8 и выкинуть весь мусор вроде пробелов, скобок и минусов, кроме цифр) - Автозамена. Напиши скрипт, заменяющий определенное слово на другое (например, слово
«дурак» на «хороший человек» в фразе «ты дурак»). Скрипт должен не пропускать слово,
если оно написано буквами в разном регистре (ДуРАк), с заменой русских букв
на похожие английские (а -> a), или через пробелы («ты — д у р а к») - Дан текст, содержащий в себе email’ы (адреса почты вроде you+me@some.domain-domain.com ). Напиши
скрипт, выводящий все email, встречающиеся в этом тексте - «Grammar Nazi». Напиши скрипт, проверяющий текст на наличие злостных ошибок:
- нет пробела после запятой, точки с запятой, восклицательного знака,
вопросительного знака, двоеточия - «жи» или «ши» написано с буквой ы
- в тексте есть слово «координально» или «сдесь», «зделал», «зделаю», «зделан»
- в тексте есть слова «а» или «но» без запятой перед ними.
- (можешь добавить еще несколько правил, если хорошо знаешь русский язык)
В случае обнаружения ошибки скрипт должен писать сообщение об этом и выводить
кусок текста с ошибкой (чтобы было понятно, что не так). - нет пробела после запятой, точки с запятой, восклицательного знака,
- Если ты сделал задачу про Grammar Nazi, сделай скрипт, которы вместо сообщения об ошибках будет
молча их исправлять.
Unicode категории (category)¶
В стандарте Unicode есть именованные категории символов (Unicode category). Категория обозначается одной буквой, и еще одна добавляется, чтобы указать подкатегорию. Например «L» это буква в любом регистре, «Lu» — буквы в верхнем регистре, «Ll» — в нижнем.
- Cc — Control
- Cf — Формат
- Co — Частное использование
- Cs — Заменитель (Surrrogate)
- Ll — Буква нижнего регистра
- Lm — Буква-модификатор
- Lo — Прочие буквы
- Lt — Titlecase Letter
- Lu — Буква в верхнем регистре
- Mc — Разделитель
- Me — Закрывающий знак (Enclosing Mark)
- Mn — Несамостоятельный символ, как умляут над буквой (Nonspacing Mark)
- Nd — Десятичная цифра
- Nl — Буквенная цифра — например, китайская, римская, руническая и т.д. (Letter Number)
- No — Другие цифры
- Pc — Connector Punctuation
- Pd — Dash Punctuation
- Pe — Close Punctuation
- Pf — Final Punctuation
- Pi — Initial Punctuation
- Po — Other Punctuation
- Ps — Open Punctuation
- Sc — Currency Symbol
- Sk — Modifier Symbol
- Sm — Математический символ
- So — Прочие символы
- Zl — Разделитель строк
- Zp — Разделитель параграфов
- Zs — Space Separator
Метасимвол это один символ указанной Unicode категории (category). Синтаксис: или если категория обозначается одним символом, для 2-символьных категорий.
Метасимвол это символ не из Unicode категории (category).
PHP regex extracting matches
The takes an optional third parameter.
If it is provided, it is filled with the results of the search.
The variable is an array whose first element contains the text that
matched the full pattern, the second element contains
the first captured parenthesized subpattern, and so on.
extract_matches.php
<?php
$times = ;
$pattern = "/(\d\d):(\d\d):(\d\d)/";
foreach ($times as $time) {
$r = preg_match($pattern, $time, $match);
if ($r) {
echo "The $match is split into:\n";
echo "Hour: $match\n";
echo "Minute: $match\n";
echo "Second: $match\n";
}
}
In the example, we extract parts of a time string.
$times = ;
We have three time strings in English locale.
$pattern = "/(\d\d):(\d\d):(\d\d)/";
The pattern is divided into three subpatterns using square
brackets. We want to refer specifically to exactly to
each of these parts.
$r = preg_match($pattern, $time, $match);
We pass a third parameter to the
function. In case of a match, it contains text parts of
the matched string.
if ($r) {
echo "The $match is split into:\n";
echo "Hour: $match\n";
echo "Minute: $match\n";
echo "Second: $match\n";
}
The contains the text that matched the full
pattern, contains text that matched the first
subpattern, the second, and
the third.
$ php extract_matches.php The 10:10:22 is split into: Hour: 10 Minute: 10 Second: 22 The 23:23:11 is split into: Hour: 23 Minute: 23 Second: 11 The 09:06:56 is split into: Hour: 09 Minute: 06 Second: 56
This is the output of the example.
Статичные регэкспы
В некоторых реализациях javascript регэкспы, заданные коротким синтаксисом /…/ — статичны. То есть, такой объект создается один раз в некоторых реализациях JS, например в Firefox. В Chrome все ок.
function f() {
// при многократных заходах в функцию объект один и тот же
var re = /lalala/
}
По стандарту эта возможность разрешена ES3, но запрещена ES5.
Из-за того, что при глобальном поиске меняется, а сам объект регэкспа статичен, первый поиск увеличивает , а последующие — продолжают искать со старого , т.е. могут возвращать не все результаты.
При поиске всех совпадений в цикле проблем не возникает, т.к. последняя итерация (неудачная) обнуляет .
Символьные классы — \d \w \s и .
\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее. У операторов , и также есть отрицания ― исоответственно
У операторов , и также есть отрицания ― исоответственно.
Например, оператор будет искать соответствия противоположенные .
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например , необходимо выделять обратным слешем .
\$\d соответствует строке, в которой после символа $ следует одна цифра -> тест
Непечатаемые символы также можно искать, например табуляцию , новую строку , возврат каретки .
Практические примеры сложных регулярных выражений
Теперь, когда вы знаете теорию и основной синтаксис регулярных выражений в PHP, пришло время создать и проанализировать некоторые более сложные примеры.
1) Проверка имени пользователя с помощью регулярного выражения
Начнем с проверки имени пользователя. Если у вас есть форма регистрации, вам понадобится проверять на правильность имена пользователей. Предположим, вы не хотите, чтобы в имени были какие-либо специальные символы, кроме «» и, конечно, имя должно содержать буквы и возможно цифры. Кроме того, вам может понадобиться контролировать длину имени пользователя, например от 4 до 20 символов.
Сначала нам нужно определить доступные символы. Это можно реализовать с помощью следующего кода:
После этого нам нужно ограничить количество символов следующим кодом:
{4,20}
Теперь собираем это регулярное выражение вместе:
^{4,20}$
В случае Perl-совместимого регулярного выражения заключите его символами ‘‘. Итоговый PHP-код выглядит так:
<?php
$pattern = '/^{4,20}$/';
$username = "demo_user-123";
if (preg_match($pattern, $username)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
2) Проверка шестнадцатеричного кода цвета регулярным выражением
Шестнадцатеричный код цвета выглядит так: , также допустимо использование краткой формы, например . В обоих случаях код цвета начинается с и затем идут ровно 3 или 6 цифр или букв от a до f.
Итак, проверяем начало кода:
^#
Затем проверяем диапазон допустимых символов:
После этого проверяем допустимую длину кода (она может быть либо 3, либо 6). Полный код регулярного выражения выйдет следующим:
^#(({3}$)|({6}$))
Здесь мы используем логический оператор, чтобы сначала проверить код вида , а затем код вида . Итоговый PHP-код проверки регулярным выражением выглядит так:
<?php
$pattern = '/^#(({3}$)|({6}$))/';
$color = "#1AA";
if (preg_match($pattern, $color)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
3) Проверка электронной почты клиента с использованием регулярного выражения
Теперь давайте посмотрим, как мы можем проверить адрес электронной почты с помощью регулярных выражений. Сначала внимательно рассмотрите следующие примеры адресов почты:
john.doe@test.com john@demo.ua john_123.doe@test.info
Как мы можем видеть, символ является обязательным элементом в адресе электронной почты. Помимо этого должен быть какой-то набор символов до и после этого элемента. Точнее, после него должно идти допустимое доменное имя.
Таким образом, первая часть должна быть строкой с буквами, цифрами или некоторыми специальными символами, такими как . В шаблоне мы можем написать это следующим образом:
^+
Доменное имя всегда имеет, скажем, имя и tld (top-level domain) – т.е, доменную зону. Доменная зона – это , , и тому подобное. Это означает, что шаблон регулярного выражения для домена будет выглядеть так:
+\.{2,5}$
Теперь, если мы соберем все в кучу, то получим полный шаблон регулярного выражения для проверки адреса электронной почты:
^+@+\.{2,5}$
В коде PHP эта проверка будет выглядеть следующим образом:
<?php
$pattern = '/^+@+\.{2,5}$/';
$email = "john_123.doe@test.info";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Надеемся, что сегодняшняя статья помогла вам при знакомстве с регулярными выражениями в PHP, а практические примеры пригодятся вам при использовании регулярных выражений в собственных PHP скриптах.
-
3875
-
35
-
Опубликовано 16/04/2019
-
PHP, Уроки программирования
str.replace(str|regexp, str|func)
Это универсальный метод поиска-и-замены, один из самых полезных. Этакий швейцарский армейский нож для поиска и замены в строке.
Мы можем использовать его и без регулярных выражений, для поиска-и-замены подстроки:
Хотя есть подводный камень.
Когда первый аргумент является строкой, он заменяет только первое совпадение.
Вы можете видеть это в приведённом выше примере: только первый заменяется на .
Чтобы найти все дефисы, нам нужно использовать не строку , а регулярное выражение с обязательным флагом :
Второй аргумент – строка замены. Мы можем использовать специальные символы в нем:
| Спецсимволы | Действие в строке замены |
|---|---|
| вставляет | |
| вставляет всё найденное совпадение | |
| вставляет часть строки до совпадения | |
| вставляет часть строки после совпадения | |
| если это 1-2 значное число, то вставляет содержимое n-й скобки | |
| вставляет содержимое скобки с указанным именем |
Например:
Для ситуаций, которые требуют «умных» замен, вторым аргументом может быть функция.
Она будет вызываться для каждого совпадения, и её результат будет вставлен в качестве замены.
Функция вызывается с аргументами :
- – найденное совпадение,
- – содержимое скобок (см. главу Скобочные группы).
- – позиция, на которой найдено совпадение,
- – исходная строка,
- – объект с содержимым именованных скобок (см. главу Скобочные группы).
Если скобок в регулярном выражении нет, то будет только 3 аргумента: .
Например, переведём выбранные совпадения в верхний регистр:
Заменим каждое совпадение на его позицию в строке:
В примере ниже две скобки, поэтому функция замены вызывается с 5-ю аргументами: первый – всё совпадение, затем два аргумента содержимое скобок, затем (в примере не используются) индекс совпадения и исходная строка:
Если в регулярном выражении много скобочных групп, то бывает удобно использовать остаточные аргументы для обращения к ним:
Или, если мы используем именованные группы, то объект с ними всегда идёт последним, так что можно получить его так:
Использование функции даёт нам максимальные возможности по замене, потому что функция получает всю информацию о совпадении, имеет доступ к внешним переменным и может делать всё что угодно.
PHP PRCE functions
We define some PCRE regex functions. They all have a preg prefix.
- — splits a string by regex pattern
- — performs a regex match
- — search and replace string by regex pattern
- — returns array entries that match the regex pattern
Next we will have an example for each function.
php> print_r(preg_split("@\s@", "Jane\tKate\nLucy Marion"));
Array
(
=> Jane
=> Kate
=> Lucy
=> Marion
)
We have four names divided by spaces. The is a character
class which stands for spaces. The function returns
the split strings in an array.
php> echo preg_match("##", "s");
1
The function looks if the ‘s’ character
is in the character class . The class stands for all
characters from a to z. It returns 1 for success.
php> echo preg_replace("/Jane/","Beky","I saw Jane. Jane was beautiful.");
I saw Beky. Beky was beautiful.
The function replaces all occurrences of
the word ‘Jane’ for the word ‘Beky’.
php> print_r(preg_grep("#Jane#", ));
Array
(
=> Jane
)
The function returns an array of words that
match the given pattern. In this example, only one word is returned in the array.
This is because by default, the search is case sensitive.
php> print_r(preg_grep("#Jane#i", ));
Array
(
=> Jane
=> jane
=> JANE
)
In this example, we perform a case insensitive grep. We put the
modifier after the right delimiter. The returned array has now three words.
Getting Started With Regular Expressions
For many beginners, regular expressions seem to be hard to learn and use. In fact, they’re far less hard than you may think. Before we dive deep inside regexp with useful and reusable codes, let’s quickly see the basics of PCRE regex patterns:
Regular Expressions Syntax
A regular expression (regex or regexp for short) is a special text string for describing a search pattern. A regex pattern matches a target string. The following table describes most common regex:
| Regular Expression | Will match… |
|---|---|
| foo | The string “foo” |
| ^foo | “foo” at the start of a string |
| foo$ | “foo” at the end of a string |
| ^foo$ | “foo” when it is alone on a string |
| a, b, or c | |
| Any lowercase letter | |
| Any character that is not a uppercase letter | |
| (gif|jpg) | Matches either “gif” or “jpg” |
| + | One or more lowercase letters |
| Any number, dot, or minus sign | |
| ^{1,}$ | Any word of at least one letter, number or _ |
| ()() | wy, wz, xy, or xz |
| Any symbol (not a number or a letter) | |
| ({3}|{4}) | Matches three letters or four numbers |
PHP Regular Expression Functions
PHP has many useful functions to work with regular expressions. Here is a quick cheat sheet of the main PHP regex functions. Remember that all of them are case sensitive.
For more information about the native functions for PHP regular expressions, have a look at the manual.
| Function | Description |
|---|---|
| preg_match() | The function searches string for pattern, returning true if pattern exists, and false otherwise. |
| preg_match_all() | The function matches all occurrences of pattern in string. Useful for search and replace. |
| preg_replace() | The function operates just like , except that regular expressions can be used in the pattern and replacement input parameters. |
| preg_split() | Preg Split () operates exactly like the function, except that regular expressions are accepted as input parameters. |
| preg_grep() | The function searches all elements of , returning all elements matching the regex pattern within a string. |
| preg_ quote() | Quote regular expression characters |
PHP regex alternation
The next example explains the alternation operator . This operator
enables to create a regular expression with several choices.
alternation.php
<?php
$names = ;
$pattern = "/Jane|Beky|Robert/";
foreach ($names as $name) {
if (preg_match($pattern, $name)) {
echo "$name is my friend\n";
} else {
echo "$name is not my friend\n";
}
}
We have eight names in the array.
$pattern = "/Jane|Beky|Robert/";
This is the search pattern. The pattern looks for ‘Jane’, ‘Beky’, or
‘Robert’ strings.
$ php alternation.php Jane is my friend Thomas is not my friend Robert is my friend Lucy is not my friend Beky is my friend John is not my friend Peter is not my friend Andy is not my friend
This is the output of the script.
Бекслеши
Если ты смотрел другие учебники по регулярным выражениям, то наверно заметил,
что бекслеш везде пишут по-разному. Где-то пишут один бекслеш:
, а здесь в примерах он повторен 2 раза: .
Почему?
Язык регулярных выражений требует писать бекслеш один раз. Однако в
строках в одиночных и двойных кавычках в PHP бекслеш тоже имеет особое
значение: .
Ну например, если написать то PHP воспримет это как
специальную комбинацию и вставит в строку только символ
(и движок регулярных выражений не узнает о бекслеше перед ним). Чтобы
вставить в строку последовательность , мы должны удвоить бекслеш
и записать код в виде .
По этой причине в некоторых случаях (там, где последовательность символов
имеет специальный смысл в PHP) мы обязаны удваивать бекслеш:
- Чтобы написать в регулярке , мы пишем в коде
- Чтобы написать в регулярке , мы удваиваем каждый
бекслеш и пишем - Чтобы написать в регулярке бекслеш и цифру (),
бекслеш надо удвоить:
В остальных случаях один или два бекслеша дадут один и тот же
результат: и вставят в строку пару
символов — в первом случае 2 бекслеша это последовательность
для вставки бекслеша, во втором случае специальной последовательности
нет и символы вставятся как есть. Проверить, какие символы вставятся в строку,
и что увидит движок регулярных выражений, можно с помощью
echo: . Да, сложно, а что поделать?
Escape-знаки
Обратная косая черта (\) в регулярных выражениях указывает, что следующий за ней символ либо является специальным знаком (как показано в следующей таблице), либо должен интерпретироваться буквально. Дополнительные сведения см. в разделе Escape-символы.
| Escape-символ | Описание | Шаблон | Число соответствий |
|---|---|---|---|
| Соответствует знаку колокольчика, \u0007. | в | ||
| В классе символов соответствует знаку BACKSPACE, \u0008. | в | ||
| Соответствует знаку табуляции, \u0009. | , в | ||
| Соответствует знаку возврата каретки, \u000D. ( не эквивалентен знаку начала новой строки, .) | в | ||
| Соответствует знаку вертикальной табуляции, \u000B. | в | ||
| Соответствует знаку перевода страницы, \u000C. | в | ||
| Соответствует знаку новой строки, \u000A. | в | ||
| Соответствует escape-знаку, \u001B. | в | ||
| nnn | Использует восьмеричное представление для указания символа (nnn состоит из двух или трех цифр). | , в | |
| nn | Использует шестнадцатеричное представление для указания символа (nn состоит ровно из двух цифр). | , в | |
| Xx | Соответствует управляющему символу ASCII, который задан как X или x, где X или x является буквой управляющего символа. | в (Ctrl-C) | |
| nnnn | Совпадение со знаком Юникода в шестнадцатеричном представлении (строго четыре цифры, представленные как nnnn). | , в | |
| Если за этим знаком следует символ, не распознанный как escape-символ из этой и других таблиц данной темы, то соответствует в точности этому символу. Например, — это то же самое, что и , а — то же самое, что и . Это позволяет обработчику регулярных выражений распознавать языковые элементы (такие как *или ?) и символьные литералы (представленные как или ). | и в |
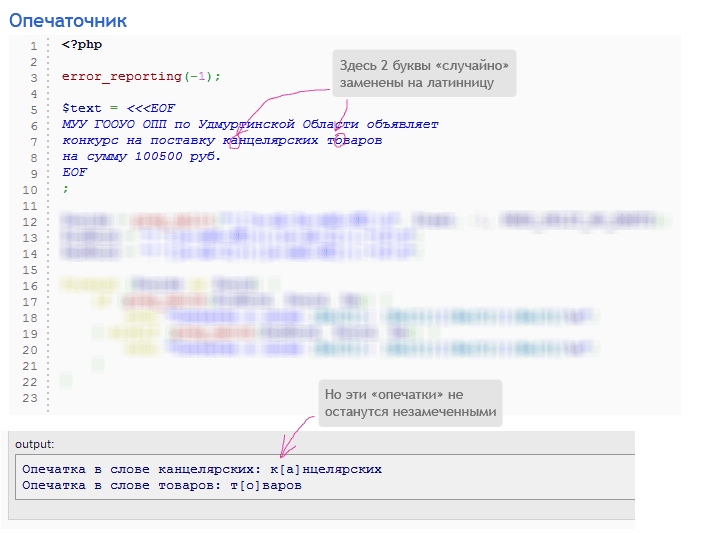
Опечаточники
Как тебе наверно известно, многие люди, занимающие государственные посты, тратят свои силы
отнюдь не на улучшение ситуации в своем городе или регионе, а на придумывание разнообразных
схем по перемещению вверенных им бюджетных средств в свои карманы.
Например, государственные органы, которые хотят провести закупки, обязаны организовать публичные торги и
разместить объявление о них на сайте госзакупок. Чтобы помешать всем желающим участвовать в тендере
(и чтобы отдать заказ «своим людям» и получить потом от них в свой карман часть денег), они заменяют в
описании заказа некоторые русские буквы на похожие на них латинские. Таким образом, не предупрежденные
заранее организации не смогут найти объявление через поиск и принять участие в конкурсе.
Давай попробуем применить наши знания языка PHP для того, чтобы вывести жуликов на чистую воду.
Задача: дан текст, содержащий слова на русском и английском языках. В некоторых словах часть русских букв
заменена на похожие на них латинские, и наоборот. Напиши программу, которая находит все такие слова,
выводит их и выделяет квадратными скобками первую замененную букву.
Для проверки работоспособности, попробуй применить программу к тексту из поля «Наименование заказа» на
странице (осторожно, спойлер!)
или
Дополнительная задача: добавь в программу автоматическое исправление найденных «опечаток».
Подсказки для глупеньких:
P.S. На сайте программистских комиксов xkcd есть комикс про регулярные выражения:
перевод, оригинал (англ.).
дальше:
Повторим? →
Описание
preg_match_all
Ищет в строке subject все совпадения с шаблоном
pattern и помещает результат в массив
matches в порядке, определяемом комбинацией флагов
flags.
После нахождения первого соответствия последующие поиски будут осуществляться
не с начала строки, а от конца последнего найденного вхождения.
Дополнительный параметр flags может комбинировать следующие значения
(необходимо понимать, что использование PREG_PATTERN_ORDER одновременно с PREG_SET_ORDER бессмысленно):
- PREG_PATTERN_ORDER
-
Если этот флаг установлен, результат будет упорядочен следующим образом:
элемент $matches содержит массив полных вхождений шаблона,
элемент $matches содержит массив вхождений первой подмаски, и так далее.
Результат работы примера:
<b>example: </b>, <div align=left>this is a test</div> example: , this is a test
Как мы видим, $out содержит массив полных вхождений шаблона,
а элемент $out содержит массив подстрок, содержащихся в тегах.
- PREG_SET_ORDER
-
Если этот флаг установлен, результат будет упорядочен следующим образом:
элемент $matches содержит первый набор вхождений,
элемент $matches содержит второй набор вхождений, и так далее.
Результат работы примера:
<b>example: </b>, example: <div align="left">this is a test</div>, this is a test
В таком случае массив $matches содержит первый набор вхождений, а именно:
элемент $matches содержит первое вхождение всего шаблона,
элемент $matches содержит первое вхождение первой подмаски, и так далее.
Аналогично массив $matches содержит второй набор вхождений, и так для каждого найденного набора.
- PREG_OFFSET_CAPTURE
-
В случае, если этот флаг указан, для каждой найденной подстроки будет указана
ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет
формат возвращаемых данных: каждое вхождение возвращается в виде массива,
в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.
Данный флаг доступен в PHP 4.3.0 и выше.
В случае, если никакой флаг не используется, по умолчанию используется
PREG_PATTERN_ORDER.
Поиск осуществляется слева направо, с начала строки. Дополнительный параметр
offset может быть использован для указания альтернативной
начальной позиции для поиска. Дополнительный параметр
offset доступен, начиная с PHP 4.3.3.
Возвращает количество найденных вхождений шаблона (может быть нулем) либо
FALSE, если во время выполнения возникли какие-либо ошибки.
|
Пример 1. Получение всех телефонных номеров из текста. |
|
Пример 2. Жадный поиск совпадений с HTML-тэгами Результат работы примера:
|
Метасимволы
В регулярных выражениях используются два типа символов: обычные символы и метасимволы. Обычные символы — это те символы, которые имеют «буквальное» значение, а метасимволы — это те символы, которые имеют «особое» значение в регулярном выражении.
Преимуществом регулярных выражений является возможность использовать условия и повторения в шаблоне. Выражения записываются при помощи метасимволов, которые специальным образом интерпретируются. Метасимвол отличается от любого другого символа тем, что имеет специальное значение.
Одним из основных метасимволов является обратный слэш (\), который меняет тип символа, следующего за ним, на противоположный. Таким образом обычный символ можно превратить в метасимвол, а если это был метасимвол, то он теряет свое специальное значение и становится обычным символом. Этот приём нужен для того, чтобы вставлять в текст специальные символы как обычные. Например, символ в обычном режиме не имеет никаких специальных значений, но — это уже метасимвол, который обозначает: «любая цифра». Символ точка в обычном режиме значит — «любой единичный символ», а экранированная точка (\.) означает просто точку.
| Метасимвол | Описание | пример |
|---|---|---|
| . | Соответствует любому одиночному символу, кроме новой строки. | /./ соответствует строке, состоящей из одного символа. |
| ^ | Соответствует началу строки. | /^cars/ соответствует любой строке, которая начинается с cars. |
| $ | Соответствует шаблону в конце строки. | /com$/ соответствует строке, заканчивающейся на com, например gmail.com |
| * | Соответствует 0 или более вхождений. | /com*/ соответствует commute, computer, compromise и т.д. |
| + | Соответствующий предыдущему символу появляется как минимум один раз. | Например, /z+oom/ соответствует zoom. |
| \ | Используется для удаления метасимволов в регулярном выражении. | /google\.com/ будет рассматривать точку как буквальное значение, а не как метасимвол. |
| a-z | Соответствует строчным буквам. | cars |
| A-Z | Соответствует буквам в верхнем регистре. | CARS |
| 0-9 | Соответствует любому числу от 0 до 9. | /0-5/ соответствует 0, 1, 2, 3, 4, 5 |
| Соответствует классу символов. | // соответствует pqr | |
| | | Разделяет перечисление альтернативных вариантов. | /(cat|dog|fish)/ соответствует cat или dog или fish |
| \d | Любая цифра. | /(\d)/ соответствует цифре |
| \s | Найти пробельный символ (в т.ч. табуляция). | /(\s)/ соответствует пробелу |
| \b | Граница слова (начало или конец). | /\bWORD/ найти совпадение в начале слова |
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Подстановки
Подстановки — это языковые элементы регулярных выражений, которые поддерживаются в шаблонах замены. Для получения дополнительной информации см. Подстановки. Приведенные в следующей таблице метасимволы являются атомарными утверждениями нулевой ширины.
| Знак | Описание | Шаблон | Шаблон замены | Входная строка | Результирующая строка |
|---|---|---|---|---|---|
| число | Замещает часть строки, соответствующую группе число. | ||||
| имя | Замещает часть строки, соответствующую именованной группе имя. | ||||
| Подставляет литерал «$». | |||||
| Замещает копией полного соответствия. | |||||
| Замещает весь текст входной строки до соответствия. | |||||
| Замещает весь текст входной строки после соответствия. | |||||
| Замещает последнюю захваченную группу. | |||||
| Замещает всю входную строку. |
PHP regex subpatterns
We can use square brackets to create subpatterns
inside patterns.
php> echo preg_match("/book(worm)?$/", "bookworm");
1
php> echo preg_match("/book(worm)?$/", "book");
1
php> echo preg_match("/book(worm)?$/", "worm");
0
We have the following regex pattern: . The is
a subpattern. The ? character follows the subpattern, which means that the subpattern
might appear 0, 1 times in the final pattern. The character is here for
the exact end match of the string. Without it, words like bookstore, bookmania would match too.
php> echo preg_match("/book(shelf|worm)?$/", "book");
1
php> echo preg_match("/book(shelf|worm)?$/", "bookshelf");
1
php> echo preg_match("/book(shelf|worm)?$/", "bookworm");
1
php> echo preg_match("/book(shelf|worm)?$/", "bookstore");
0
Subpatterns are often used with alternation. The
subpattern enables to create several word combinations.
Built-in Regular expression Functions in PHP
PHP has built in functions that allow us to work with regular functions which we will learn in this PHP Regular Expressions tutorial. Let’s look at the commonly used regular expression functions in PHP.
- preg_match() in PHP – this function is used to perform pattern matching in PHP on a string. It returns true if a match is found and false if a match is not found.
- preg_split() in PHP – this function is used to perform a pattern match on a string and then split the results into a numeric array
- preg_replace() in PHP – this function is used to perform a pattern match on a string and then replace the match with the specified text.
Below is the syntax for a regular expression function such as PHP preg_match(), PHP preg_split() or PHP preg_replace().
<?php
function_name('/pattern/',subject);
?>
HERE,
- “function_name(…)” is either PHP preg_match(), PHP preg_split() or PHP preg_replace().
- “/…/” The forward slashes denote the beginning and end of our PHP regex tester function
- “‘/pattern/’” is the pattern that we need to matched
- “subject” is the text string to be matched against
Let’s now look at practical examples that implement the above PHP regex functions.
Parse Apache Logs
Most websites are running on the Apache webserver. If your website does, you can easily use PHP and regular expressions to parse Apache logs.
//Logs: Apache web server //Successful hits to HTML files only. Useful for counting the number of page views. '^((?#client IP or domain name)S+)s+((?#basic authentication)S+s+S+)s+]+)]s+"(?:GET|POST|HEAD) ((?#file)/+?.html?)??((?#parameters)+)? HTTP/+"s+(?#status code)200s+((?#bytes transferred)+)s+"((?#referrer)*)"s+"((?#user agent)*)"$' //Logs: Apache web server //404 errors only '^((?#client IP or domain name)S+)s+((?#basic authentication)S+s+S+)s+]+)]s+"(?:GET|POST|HEAD) ((?#file)+)??((?#parameters)+)? HTTP/+"s+(?#status code)404s+((?#bytes transferred)+)s+"((?#referrer)*)"s+"((?#user agent)*)"$'
» Source






