Индексация wordpress сайтов. файл robots.txt и мета-тег robots
Содержание:
- Практическая реализация заголовка X-Robots-Tag
- Другие полезные мета-теги
- Атрибут noindex: что это и чем отличается от nofollow?
- Использование метатега robots для блокирования доступа к сайту
- Что такое файл TXT??
- Мета-тег
- Как правильно прописать nofollow?
- Updates from 29/08/2018:
- How to avoid crawlability and (de)indexation mistakes
- Причины для запрета попадания пагинации в индекс
- В чем отличие между noindex и nofollow
- SEO benefits of using robots and X-Robots-Tag
- What is a Noindex Meta Tag?
- Summary
- Генераторы robots.txt
- What Is Robots.txt?
Практическая реализация заголовка X-Robots-Tag
Заголовок можно добавить в HTTP-ответы с помощью файлов конфигурации в серверном ПО сайта. Например, на серверах Apache такие настройки хранятся в файлах .htaccess и httpd.conf. Преимущество использования заголовка в HTTP-ответах состоит в том, что с его помощью можно задать директивы сканирования на уровне всего сайта, а поддержка регулярных выражений обеспечивает дополнительную гибкость.
Например, чтобы добавить заголовок с директивой в HTTP-ответ для PDF-файлов со всего сайта, включите небольшой фрагмент кода в корневой файл .HTACCESS/HTTPD.CONF (Apache) или CONF (NGINX).
Заголовки можно использовать для тех файлов, для которых HTML-метатеги robots недоступны, например для изображений. В приведенном ниже примере директива добавляется для файлов изображений (PNG, JPEG, JPG, GIF) на всём сайте:
Заголовки также можно задать для отдельных статических файлов.
Другие полезные мета-теги
Ниже я приведу еще несколько мета-тегов, которые напрямую не влияют на индексацию и ранжирование страниц, но их тоже важно знать специалисту по SEO
Мета-тег Viewport
Синтаксис
<meta name="viewport" content="width=device-width, initial-scale=1" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте. Актуальность тега возросла с переходом значительной части аудитории в Mobile. В случае применения адаптивной верстки, наличие этого тега позволяет правильно учитывать размер используемого устройства (ПК, планшет, смартфон).
Значение адаптирует ширину окна просмотра к экрану устройства. Значение обеспечивает соотношение 1:1 между пикселями CSS и независимыми пикселями устройства.
В случае отсутствия этого тега страница будет отображаться как на десктопе, даже если адаптивная верстка настроена корректно. Поэтому при анализе соответствия сайта требованиям для мобильных устройств, наличие мета-тега ViewPort является обязательным и для Google, и для Яндекса.
Мета-тег NoYDIR
Синтаксис
<meta name="slurp" content="noydir" /> или <meta name="robots" content="noydir" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте. Этот тег используется в следующих случаях. Если сайт был добавлен в каталог Yahoo!, то некоторые поисковые системы могут выводить описание сайта, взятое из Yahoo! Directory. Если это не нужно, то добавляется этот тег.
Мета-тег Generator
Синтаксис
<meta name="generator" content="WordPress 4.6.6" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте.
Эти мета-теги используются некоторыми CMS с целью предоставления информации о том, на каком движке или на какой версии движка сделан данный сайт. Если он указан, специалисту будет легко определить CMS сайта.
Мета-теги Author и Copyright
Синтаксис
<meta name="author" content="Иван Иванович" />
<meta name="copyright" lang="ru" content="ООО Ромашка" />
Тег должен находиться внутри контейнера <head>…</head> в любом месте.
Теги используются соответственно для указания авторства и авторских прав. Не стоит путать эти мета-теги с возможностями микроразметки. Если необходимо корректно настроить авторство, лучше обратиться к этим статьям:
Атрибут noindex: что это и чем отличается от nofollow?
Многие начинающие вебмастера ломают голову, не понимая, чем noindex отличается от nofollow. Все просто:
- nofollow — применяется к ссылкам
- noindex — применяется к тексту
Если вы хотите запретить текст на всей странице сайта для индексации, но при этом учитывать ссылки, на странице нужно прописать следующий код:
Если вы хотите закрыть часть текста, то в Google нет такого атрибута, но в Яндексе это возможно. Тег noindex был внедрен поисковиком Яндекс, так как раньше он не понимал nofollow, а ненужные ссылки нужно было как-то закрывать от роботов.
Но в 2010 году поисковая система начала работать с атрибутом rel=”nofollow”, при этом noindex не исчез, а остался отвечать за скрытие текста. Теперь, если вы хотите закрыть от индексации текст или например анкор ссылки, пропишите команду:
<noindex><a href=”url”>анкор ссылки</a></noindex>
Сама ссылка будет открыта для перехода роботами поисковых систем, не учтется только ее текст (анкор). Так же можно закрывать не только анкоры ссылок, но и контент.
Например это удобно было, когда Яндекс ввел новый алгоритм Баден-Баден, который накладывал санкции за seo тексты. Стоило закрыть портянки текста в noindex, и можно было выйти из под этого фильтра, причем не потерять позиции в Google, так как поисковая система Google не учитывает тег <noindex></noindex>.
Использование метатега robots для блокирования доступа к сайту
Данный метод запрета индексации страниц сайта встречается гораздо реже в повседневной жизни. Как следствие происходит это из-за что разработчики большинства CMS просто не обращают на это внимания/забывают/забивают. И тогда ответственность за поведение роботов на сайте полностью ложится на плечи вебмастеров, которые в свою очередь обходятся простейшим вариантом – robots.txt.
Но продвинутые вебмастера, которые в теме особенностей индексации сайтов и поведения роботов, используют метатег robots.
И снова небольшая выдержка из руководства от Google:
Внушает оптимизм, не правда ли? И еще:
Следовательно, все страницы, которые мы хотим запретить к индексации, а так же исключить их из индекса, если они уже проиндексированы (насколько я понял, это касается и доп. индекса Гугла), необходимо на всех таких страницах поместить метатег
Что еще более важно, эти самые страницы не должны быть закрыты через robots.txt!
Немного побуду кэпом и расскажу, какие еще значения (content=»…») может принимать мататег robots:
- noindex – запрещает индексацию страницы
- nofollow – запрещает роботу следовать по ссылкам на странице
- index, follow – разрешает роботу индексацию страницы и переход по ссылкам на этой странице
- all – аналогично предыдущему пункту. По большому счету, бесполезная директива, эквивалентна отсутствию самого метатега robots
- none – запрет на индексацию и следование по ссылкам, эквивалентно сочетанию noindex,nofollow
- noarchive – запрет поисковику выводить ссылку на кеш страницы (для Яндекса это «копия», для Google это «сохраненная копия»)
Так как в справке Яндекса нижеследующие параметры не описаны, то они, скорее всего, там и не сработают. Так что эти параметры только для Google:
- noimageindex – запрет на индексацию изображений на странице
- nosnippet – запрет на вывод сниппета в результатах поиска (при этом так же удаляется и сохраненная копия!)
- noodp – запрет для Google на вывод в качестве сниппета описания из каталога DMOZ
Вроде все, осталось только сказать, что количество пробелов, положение запятой и регистр внутри content=»…» здесь не играет никакой роли, но все же для красоты лучше писать как положено (с маленькой буквы, без пробелов и разделяя атрибуты запятой).
Короче говоря, чтобы полностью запретить индексацию ненужных страниц и появление их в поиске необходимо на всех этих страницах разместить метатег .
Так что если вам известны все страницы (наборы страниц, категории и т.д.), которые не должны попасть в индекс и есть доступ к редактированию их содержания (конкретно, содержания внутри тега ), то можно обойтись без запрещающих директив в файле robots.txt, но разместив на страницах метатег robots. Данный вариант, как вы понимаете, является эффективным и предпочтительным.
Рекомендую к прочтению:
- Мануал Google «Блокировка индексирования при помощи атрибута noindex»
- Мануал Яндекса «Как удалить страницы из поиска»
Итак, у нас остался последний нераскрытый вопрос, и он о внутренних ссылках.
Что такое файл TXT??
НКНК — это простой текстовый файл.
Файл TXT — это стандартный текстовый документ, содержащий неформатированный текст. Он распознается любой программой для редактирования текста или обработки текста, а также может обрабатываться большинством других программ.
Файл TXT открыт в Microsoft Notepad
Файлы TXT полезны для хранения информации в виде простого текста без специального форматирования, кроме основных шрифтов и стилей шрифтов. Файл обычно используется для записи заметок, указаний и других подобных документов, которые не должны отображаться определенным образом. Если вы хотите создать документ с более широкими возможностями форматирования, например, отчет, информационный бюллетень или резюме, вам следует обратиться к файлу .DOCX, который используется популярной программой Microsoft Word.
Если у вас есть компьютер под управлением Windows, Notepad и Wordpad, поставляемые в комплекте с операционной системой (ОС) и позволяющие создавать и редактировать файлы TXT. Если у вас есть компьютер с MacOS (OS X), TextEdit поставляется в комплекте с ОС и является хорошим выбором для создания и редактирования файлов TXT.
ПРИМЕЧАНИЕ: Различные аппаратные устройства, такие как смартфоны и Amazon Kindle, а также веб-браузеры, такие как Chrome и Firefox, также распознают простые текстовые файлы.
Общие имена файлов TXT
Новый текстовый документ.txt — имя файла по умолчанию Microsoft Windows предоставляет новые текстовые документы, созданные с помощью контекстного меню (щелкните правой кнопкой мыши на рабочем столе и выберите Создать и rarr; Текстовый документ ).
README.txt — текстовый файл, обычно включаемый в установщики программного обеспечения и содержащий информацию о программном обеспечении. Пользователи должны часто читать этот файл перед использованием программного обеспечения.
Программы, открывающие обычный текстовый файл.
|
|
|
|
|
Мета-тег
Начнем с базовых пониманий. Мета-тег — это служебная информация для страницы, которая указывается в документе в верхнем блоке <head></head> с HTML разметкой.
Что такое мета-тег robots?
В нашем случае, мета-тег с атрибутом name=“robots” дает указание роботам всех поисковых систем, без исключения. Так же, есть name=“googlebot”, виден только Google, и name=“yandex”, соответственно только для Yandex поисковика.
В коде это выглядит так:
<!DOCTYPE html> <html><head> <meta name="robots" content="noindex" /> (…) </head> <body>(…)</body> </html>
Атрибут content может принимать такие параметры как:
- “noindex” — ставит запрет на индексацию контента, но ссылки в документе все еще видны для поисковых роботов и открыты для просмотров и переходов на них
- “nofollow” — закрывает все ссылки на данной странице от индексации. Это касается как внешних, так и внутренних.
Варианты использования meta тега robots с noindex и nofollow
Возможны такие варианты использования:
<meta name="robots" content="index, follow"/> <!-- — включена индексация страницы и ссылок. Стоит по умолчанию для каждого сайта. --> <meta name="robots" content="noindex, follow"/> <!-- — запрет на индексацию контента страницы, но разрешен переход и просмотр ссылок. --> <meta name="robots" content="index, nofollow"/> <!-- — включена индексация, но запрещен переход и просмотр ссылок. --> <meta name="robots" content="noindex, nofollow"/> <!-- — запрет на индексацию и переход по ссылкам страницы. -->
Перечисленные варианты также можно использовать для скрытия от определенных поисковых систем, таких как Yandex и Google. Возможные варианты атрибута name видно выше, а в коде это может выглядеть так:
<meta name="googlebot" content="noindex, follow" />.
Стоит подбирать комбинацию атрибутов четко под свои цели и задачи. Давайте рассмотрим некоторые из них.
Когда нам нужен мета-тег “robots” со значением “noindex” или “nofollow”?
Мета-тег следует использовать на следующих страницах:
- со служебной информацией(админ. панель, логи сервера);
- дублирующийся контент(пагинация, архивы, теги).
А также в случаях:
- когда следует закрыть страницу от индексирования, но оставить возможность просматривать ссылки;
- когда хотите удалить документ из index и не допустить просмотра ссылок поисковыми роботами;
- когда нужно закрыть переход по ссылкам уже индексированного документа.
Рекомендуем
Операторы поиска Google
Подробнее
Как правильно прописать nofollow?
Это сейчас nofollow позволяет управлять каждой ссылкой отдельно, но когда-то данное значение можно было задействовать только в мета-теге, который закрывал от поисковой системы абсолютно все ссылки на странице. И для запрета перехода по отдельным ссылкам вебмастерам приходилось блокировать их URL в robots.txt.
Robots Nofollow
Эти мета-теги так и остались по сей день. Если вы хотите закрыть от индексации все ссылки, содержащиеся на определенной странице, то на этой странице нужно прописать такой код:
Важно не путать данный тег с двумя нижеприведенными кодами, content=»none» и content=”noindex, nofollow” блокируют доступ ботов ко всей странице, а не только к ее ссылкам. Поэтому, если вы хотите чтобы страницы индексировались, то ни в коем случае не прописывайте для них два вот этих тега:
Rel=»Nofollow»
Выше мы рассмотрели варианты, как запретить переход поисковых роботов по всем ссылкам на страницах. Но еще можно назначить запрет на переход к конкретной ссылке.
Updates from 29/08/2018:
I wanted to take the time and mention the new figures from 29th of August 2018.
The number of websites that I analyze has increased dramatically. The original article referred to the data extracted from 50,000 hotel websites. Now I analyze ~875,000 unique hotel websites (unique domains).
The findings from these 875,000+ hotel websites shows that 1.502% of hotel websites use NOINDEX or NONE as their meta robots value.
The percentage doesn’t seem high, but that’s over 13,000 of hotel websites that effectively block all search engine bots from indexing their websites.
Granted, some of them are doing this while performing maintenance on their websites. Other websites are actually trying to keep a low profile and display their business only via direct linking.
How to avoid crawlability and (de)indexation mistakes
You want to show all valuable pages, avoid duplicate content, issues and keep specific pages out of the index. If you manage a huge website then crawl budget management is another thing to pay attention to.
Let’s have a look at the most common mistakes people make regarding robots directives.
Mistake #1: Adding noindex directives to pages disallowed in robots.txt
Never disallow crawling of content that you’re trying to get deindexed in robots.txt. Doing so prevents search engines from recrawling the page and discovering the noindex directive.
If you feel you may have made that mistake in the past, crawl your site with Ahrefs Site Audit. Look for pages with “Noindex page receives organic traffic” errors.
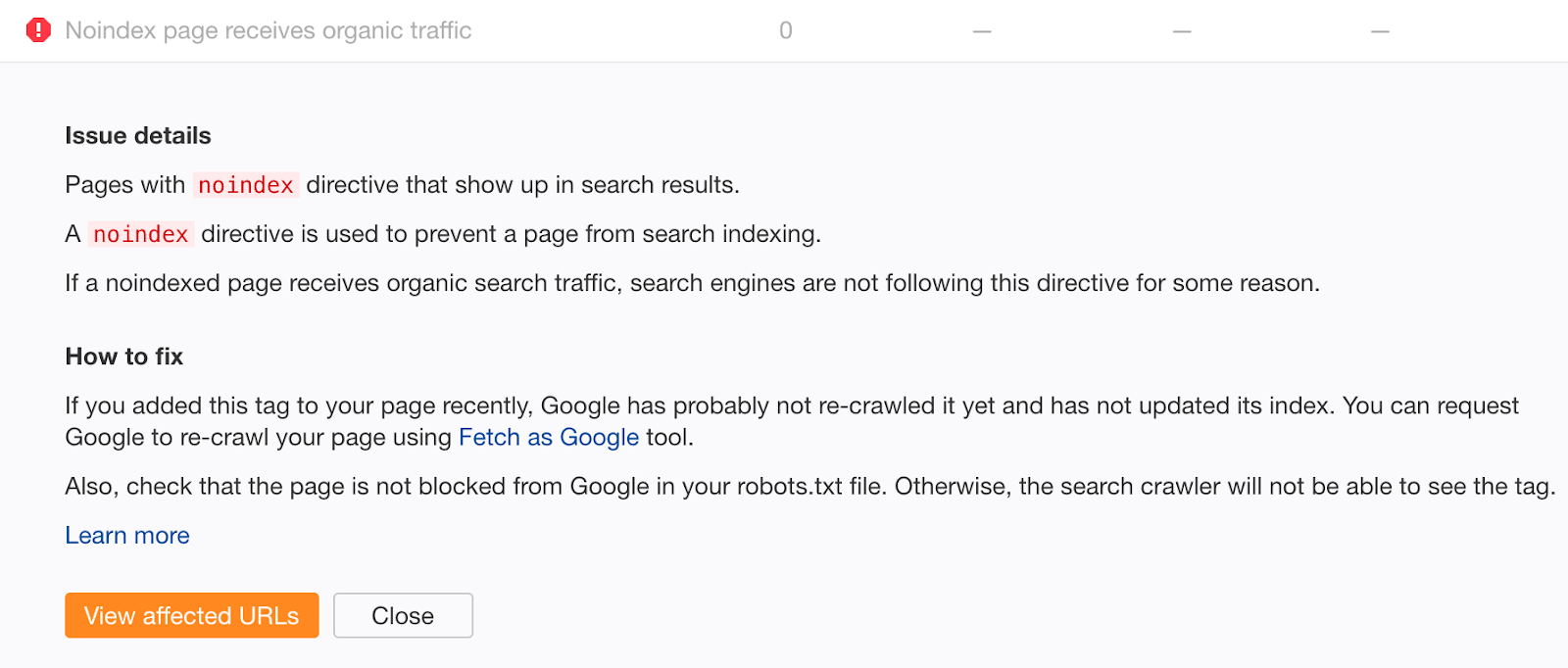
Noindexed pages that receive organic traffic are clearly still indexed. If you didn’t add the noindex tag recently, chances are this is due to a crawl block in your robots.txt file. Check for issues and fix them as appropriate.
Mistake #2: Bad sitemaps management
If you’re trying to get content deindexed using a meta robots tag or x‑robots-tag, don’t remove it from your sitemap until it’s been successfully deindexed. Otherwise, Google may be slower to recrawl the page.
To potentially speed up the deindexing process further, set the lastmod date in your sitemap to the date you added the noindex tag. This encourages recrawling and reprocessing.
Sidenote. John is talking about 404 pages here. That said, we’re assuming that this also makes sense for other changes like when you add or remove a noindex directive.
IMPORTANT NOTE
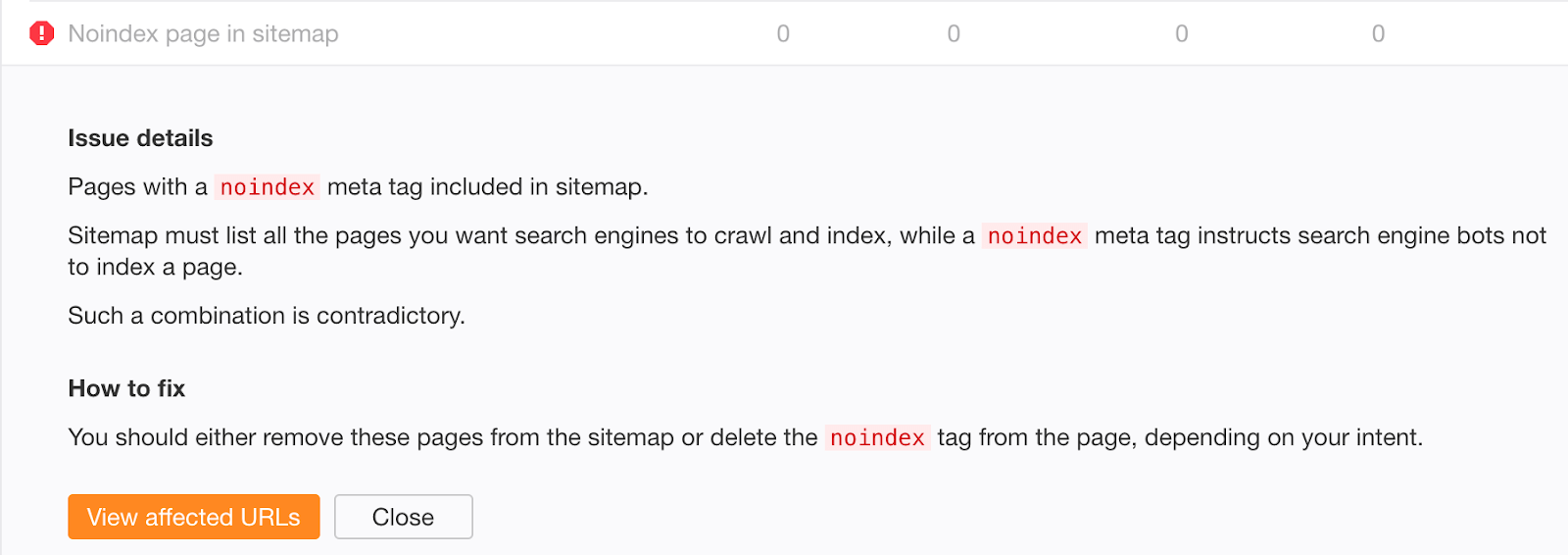
Don’t include noindexed pages in your sitemap in the long-term. Once content has been deindexed, remove it from your sitemap.
If you’re worried that old, successfully deindexed content may still exist in your sitemap, check the “Noindex page sitemap” error in Ahrefs Site Audit.
Mistake #3: Not removing noindex directives from the production environment
Preventing robots from crawling and indexing anything in the staging environment is a good practice. However, it sometimes gets pushed into production, forgotten, and your organic traffic plunges.
Even worse, the organic traffic drop might not be that noticeable if you’re involved in a site migration using 301 redirects. If the new URLs contain the noindex directive or are disallowed in robots.txt, you’ll still receive organic traffic from the old ones for some time. It can take Google up to a few weeks to deindex the old URLs.
Whenever there are such changes on your website, keep an eye on the “Noindex page” warnings in Ahrefs Site Audit:
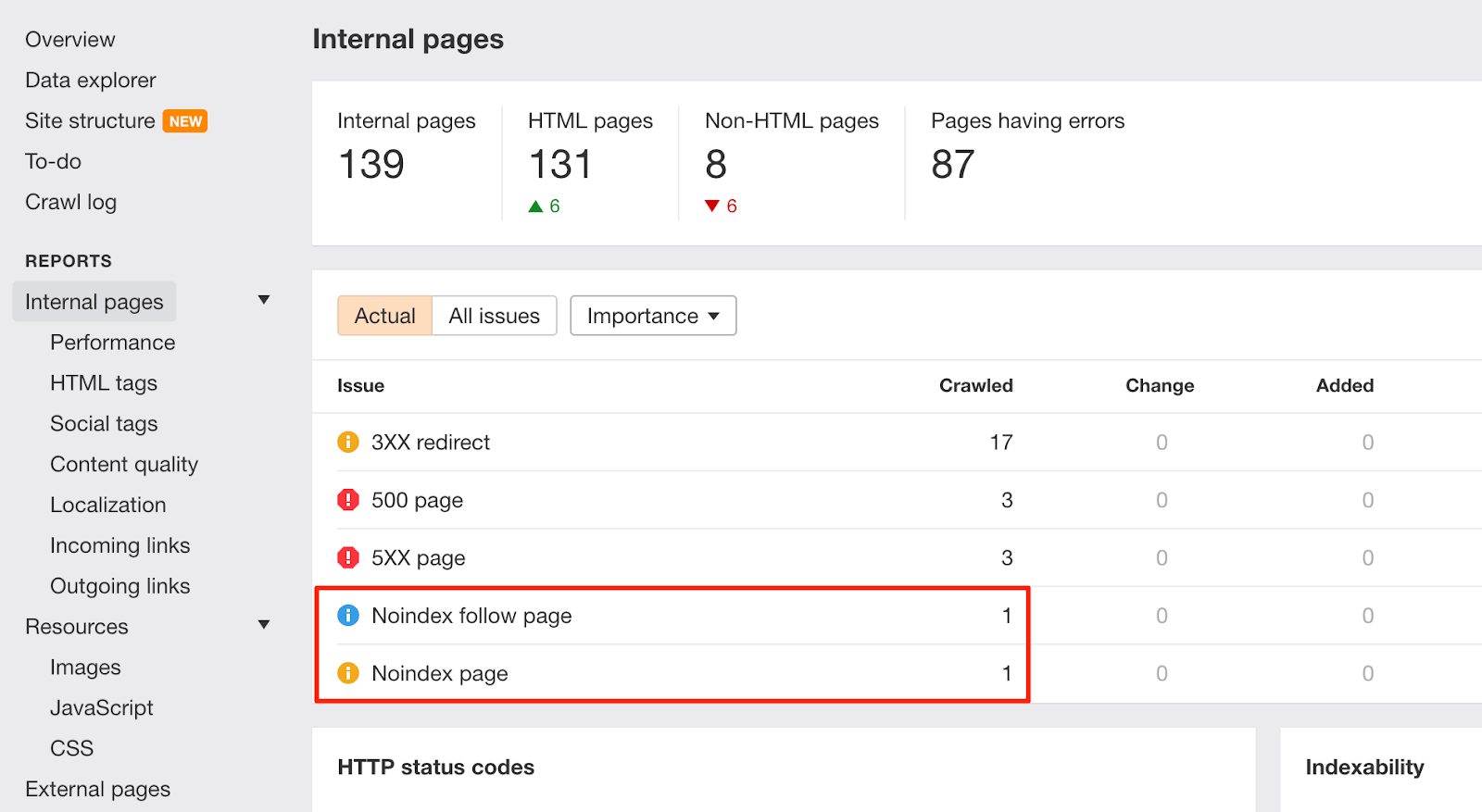
To help prevent similar issues in the future, enrich the dev team’s checklist with instructions for removing disallow rules from robots.txt and noindex directives before pushing to production.
Mistake #4: Adding “secret” URLs to robots.txt instead of noindexing them
Developers often try to hide pages about upcoming promotions, discounts, or product launches by disallowing access to them in the site’s robots.txt file. This is bad practice because humans can still view a robots.txt file. As such, these pages are easily leaked.
Fix this by keeping “secret” pages out of robots.txt and noindexing them instead.
Причины для запрета попадания пагинации в индекс
В случае, если ваш шаблон поддерживает формирования пагинации и для нее не прописан noindex, то она будет формироваться автоматически, без участия админ-панели WordPress. Несмотря на правильную цель, с учетом реализации, попадание таких страниц в выдачу (к примеру Яндекса) только пессимизирует проект. Для коммерции это спровоцирует падение в органике товаров.
Эта ВордПресс рубрика не привносит ничего нового, не добавляет ценности ресурсу, но имеет канонические адреса и содержит много внутренних ссылок с заимствованных из других материалов вырезками.
Говоря про простановку title & description надо знать также и то, что они созданы автоматически и по большей части нечитабельны и содержат кучу ключей и предлогов. В самой системе нельзя запрещать их автоматическое генерирование.
В чем отличие между noindex и nofollow
Первое существенное отличие их в том, что первый был виден ранее для Google, а второй — только для Яндекса и Rambler. В настоящее время Яндекс также научился распознавать Ноуфоллоу, который работает только для ссылок, а Ноуиндекс — для любого кода сайта.
Применение Nofollow не превращает ссылку в невидимую, а всего лишь указывает, что по ней не нужно идти и индексировать документ, на который она ведет. Поисковый робот индексирует эту гиперссылку, но вес с сайта не передается, если она ведет на чужой ресурс. Работает этот атрибут для всех поисковиков.
Что касается тега Noindex, то с ним работает только Яндекс. Гугл же просто проигнорирует его. Использовать его нужно в тех случаях, когда вы хотите закрыть какой-то участок страницы — текст, картинку или ссылку — от индексации. Поисковик контент распознает, но впоследствии выкидывает из индекса. Эта мера установлена для полного анализа страницы и процедуры наложения возможных санкций за нарушения.
SEO benefits of using robots and X-Robots-Tag
Let’s examine how the robots meta tag and the X-Robots-Tag help in search engine optimization and when you should use them.
1. Choosing what pages to index
Not all website pages can attract organic visitors. If indexed, some of them might actually harm the site’s search visibility. These are the types of pages that are usually blocked from indexing with the help of noindex:
- duplicated pages
- sorting options and filters
- search and pagination pages
- technical pages
- service notifications (about a sign up process, completed order, etc.)
- landing pages designed for testing ideas
- pages that are in progress of development
- information that isn’t up-to-date yet (future deals, announcements, etc.)
- outdated pages that don’t bring any traffic
- pages you need to block from certain search crawlers
3. Keeping the link juice
Blocking links from crawlers with the help of nofollow, you can keep the page’s link juice because it won’t be passed to other sources though external or internal links.
4. Optimizing the crawl budget
The bigger a site is, the more important it is to direct crawlers to the most valuable pages. If search engines crawl a website inside and out, the crawl budget will simply end before bots reach the content helpful for users and SEO. This way, important pages won’t get indexed or will get to the index behind the desired schedule.
What is a Noindex Meta Tag?
A ‘noindex’ tag tells search engines not to include the page in search results.
The most common method of noindexing a page is to add a tag in the head section of the HTML, or in the response headers. To allow search engines to see this information, the page must not already be blocked (disallowed) in a robots.txt file. If the page is blocked via your robots.txt file, Google will never see the noindex tag and the page might still appear in search results.
To tell search engines not to index your page, simply add the following to the </head> section:
<meta name=”robots” content=”noindex, follow”>
The second part of the content tag here indicates that all the links on this page should be followed, which we’ll discuss below.
Alternatively, the noindex tag can be used in an X-Robots-Tag in the HTTP header:
X-Robots-Tag: noindex
For more information see Google Developers’ post on
Summary
The robots meta tag and the x-robots tag serve for managing how pages are indexed and shown in the search results. They differ in utilization: the robots meta tag is included in the page code, while the X-Robots-Tag is specified in the configuration file. Remember some of their other important characteristics:
- The robots.txt file helps search bots crawl pages correctly, while the robots meta tag and X-Robots-Tag influence how content gets to the index. All three are vital for technical optimization.
- Both the robots meta tag and x-robots tag are used for blocking page indexing but the latter gives robots instructions before they crawl pages, saving the crawl budget.
- If robots.txt prevents bots from crawling a page, the robots meta tag or x-robots directives won’t work.
- Mistakes made while setting the robots meta tag and the x-robots tag can lead to incorrect indexing issues and website performance problems. Set the directives carefully or trust it to an experienced webmaster.
Post Views: 3,083

Kelly Breland
Kelly Breland is a Digital Marketing Manager at SE Ranking with experience in SEO, digital and content marketing. She is a persistent advocate of using content marketing to build a solid brand. In her spare time, she is engaged in gardening.
Генераторы robots.txt
Генераторы файла robots.txt — инструменты, которые позволяют ввести вводные данные и получить готовый список директив, например:
- Генератор от pr-cy.ru
- Генератор от случайного агенства
- Генератор от случайного агенства-2
Однако, стоит понимать, что необходим понимать что и каким образом закрывается на сайте.
Например, логичное с одной стороны закрытие GET-параметров, может привести к потери качественных страниц, которые уже занимают хорошие позиции в индексе. Другой пример — закрытие страниц пагинации, которые тоже хорошо могут отдаваться в поиске. Поэтому, до внесения изменений в robots с помощью генераторов, следует детально изучить выдачу, а также способы формирования контента на рабочем проекте.
What Is Robots.txt?
A robots.txt file tells crawlers what should be crawled.
It’s part of the robots exclusion protocol (REP).
Googlebot is an example of a crawler.
Google deploys Googlebot to crawl websites and record information on that site to understand how to rank the site in Google’s search results.
You can find any site’s robots.txt file by add /robots.txt after the web address like this:
www.mywebsite.com/robots.txt
Here is what a basic, fresh, robots.txt file looks like:
The asterisk * after user-agent tells the crawlers that the robots.txt file is for all bots that come to the site.
Advertisement
Continue Reading Below
The slash / after “Disallow” tells the robot to not go to any pages on the site.
Here is an example of Moz’s robots.txt file.
You can see they are telling the crawlers what pages to crawl using user-agents and directives. I’ll dive into those a little later.






