Ключи sql
Содержание:
Первичный и уникальный ключи
Скрыть рекламу в статье
Первичный и уникальный ключи
Первичные ключи являются одним из основных видов ограничений в базе данных. Они применяются для однозначной идентификации записей в таблице. Допустим, мы храним в базе данных список людей. Вполне вероятно, что могут появиться два (или больше) человека с одинаковыми фамилией, именем и отчеством Как же гарантированно отличить одного человека от другого (конечно. речь идет о том, чтобы отличить одного человека от другого на основании информации, хранящейся в базе данных)?
В данном случае «человек» представлен одной записью в таблице, поэтому можно задаться более общим вопросом — как отличить одну запись в (любой) таблице от другой записи в этой же таблице. Для этого используются ограничения — первичные кпочи. Первичный ключ представляет собой одно или несколько полей в таблице, сочетание которых уникально для каждой записи. Для одной таблицы не существует повторяющихся значений первичного ключа.
Уникальные кчочи несут аналогичную нагрузку — они также служат для однозначной идентификации записей в таблице. Отличие первичных ключей от уникальных состоит в том, что первичный ключ может быть в таблице только один, а уникатьных ключей — несколько. Надо отметить, что и первичный и уникальный ключ могут быть использованы в качестве ссылочной основы для внешних ключей (см. далее).
Синтаксис создания первичного и уникального ключа на основе единственного поля следующий:
<pkukconstraint> = {PRIMARY KEY |
UNIQUE}
Примеры первичных и уникальных ключей:
CREATE TABLE pkuk(
pk NUMERIC(15,0) NOT NULL PRIMARY KEY, /*первичный ключ*/
ukl VARCHAR(SO) NOT NULL UNIQUE,/*уникальный ключ */
uk2 INTEGER NOT NULL UNIQUE /* еще уникальный ключ */);
Синтаксис создания первичного и уникального ключей на основе нескольких полей:
<pkuktconstraint> = {PRIMARY KEY |
UNIQUE) ( col )
Такой синтаксис позволяет создавать ключи на основе комбинации полей. Вот примеры создания первичных и уникальных ключей из нескольких полей:
CREATE TABLE pkuk2(
Number1 INTEGER NOT NULL,
Namel VARCHAR(SO) NOT NULL,
Kol INTEGER NOT NULL,
Stoim NUMERIC(15,4) NOT NULL,
CONSTRAINT pkt PRIMARY KEY (Numberl, Namel), /*первичный ключ pkt на
основе двух полей*/
CONSTRAINT uktl UNIQUE (kol, Stoim) ); /*уникальный ключ uktl на основе
двух полей*/
Обратите внимание, что все поля, входящие в состав первичного и уникального ключей, должны быть объявлены как NOT NULL, так как эти ключи не могутиметь неопределенного значения. Помимо создания ограничения первичных и уникальных ключей в момент создания таблицы имеется возможность добавлять ограничения в уже существующую таблицу
Для этого используется предложение DDL: ALTER TABLE. Синтаксис добавтения ограничений первичного или уникального ключа в существующую таблицу аналогичен описанному выше:
Помимо создания ограничения первичных и уникальных ключей в момент создания таблицы имеется возможность добавлять ограничения в уже существующую таблицу. Для этого используется предложение DDL: ALTER TABLE. Синтаксис добавтения ограничений первичного или уникального ключа в существующую таблицу аналогичен описанному выше:
ALTER TABLE tablename
ADD {PRIMARY KEY | UNIQUE) ( col )
Давайте рассмотрим пример создания первичного и уникального ключа с помощью ALTER TABLE. Сначала создаем таблицу:
CREATE TABLE pkalter(
ID1 INTEGER NOT NULL,
ID2 INTEGER NOT NULL,
UID VARCHAR(24));
Затем добавляем ключи. Сначала первичный:
ALTER TABLE pkalter
ADD CONSTRAINT pkall PRIMARY KEY (idl, id2);
Затем уникальный ключ:
ALTER TABLE pkalter
ADD CONSTRAINT ukal UNIQUE (uid) ;
Важно отметить, что добавление (а также удаление) ограничений первичных и уникальных ключей к таблице может производить только владелец этой таблицы или системный администратор SYSDBA (подробнее о владельцах и пользователе SYSDBA см. главу «Безопасность в InterBase: пользователи, роли и права») (ч
4).
Оглавление книги
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Определение связей между сущностями
Реляционные базы данных позволяют объединять информацию, принадлежащую разным сущностям.
Отношение — это ситуация, при которой одна сущность ссылается на первичный ключ второй сущности. Как, например, сущности Дом и Хозяин на предыдущем рисунке.
Отношения определяются в процессе проектирования базы. Для этого следует проанализировать сущности и выявить логические связи, существующие между ними.
Тип отношения определяет количество записей сущности, связанных с записью другой сущности. Отношения делятся на три основных типа, о которых рассказано далее.
Один-к-одному
Каждой записи первой сущности соответствует только одна запись из второй сущности. А каждой записи второй сущности соответствует только одна запись из первой сущности. Например, есть две сущности: Люди и Свидетельства о рождении. И у одного человека может быть только одно свидетельство о рождении.
Один-ко-многим
Каждой записи первой сущности могут соответствовать несколько записей из второй сущности. Однако каждой записи второй сущности соответствует только одна запись из первой сущности. Например, есть две сущности: Заказ и Позиция заказа. И в одном заказе может быть много товаров.
Многие-ко-многим
Каждой записи первой сущности могут соответствовать несколько записей из второй сущности. Однако и каждой записи второй сущности может соответствовать несколько записей из первой сущности. Например, есть две сущности: Автор и Книга. Один автор может написать много книг. Но у книги может быть несколько авторов.
По критерию обязательности отношения делятся на обязательные и необязательные.
- Обязательное отношение означает, что для каждой записи из первой сущности непременно должны присутствовать связанные записи во второй сущности.
- Необязательное отношение означает, что для записи из первой сущности может и не существовать записи во второй сущности.
А что там внутри. Пример нормализации
Разберём устройство реляционной БД подробнее на примере. Позже это поможет нам понимать и сравнивать базы разных типов.
Допустим, у нас есть база данных, в которой всего одна таблица — Messages. В ней хранится информация о телефонных разговорах клиентов и операторов компании по ремонту техники.
Каждая строка этой таблицы содержит данные о звонке клиента по его проблеме и ответ оператора, а также дату обращения.
Телефон у компании многоканальный. Поэтому одному и тому же оператору могут звонить разные клиенты, а один и тот же клиент может попадать на разных операторов с разными вопросами.
Создание файла базы данных
При запуске Access открывается диалоговое окно — Окно запуска, в котором предлагается создать новую БД, запустить Мастера БД или открыть существующую БД.
В Access поддерживаются два способа создания БД. Можно создать пустой файл БД, а затем разрабатывать таблицы, формы, отчеты и другие объекты, добавляя их в БД. Такой способ является профессиональным и наиболее гибким, но требует отдельного определения каждого элемента БД. При выборе такого способа создания БД надо в окне запуска установить флажок Новая база данных. В раскрывшемся окне Файл новой базы данных следует выбрать каталог и задать имя создаваемой БД. Раскроется Окно базы данных.
Вниманию студентов! Студенческие БД должны создаваться в директории StudentGRNNN.
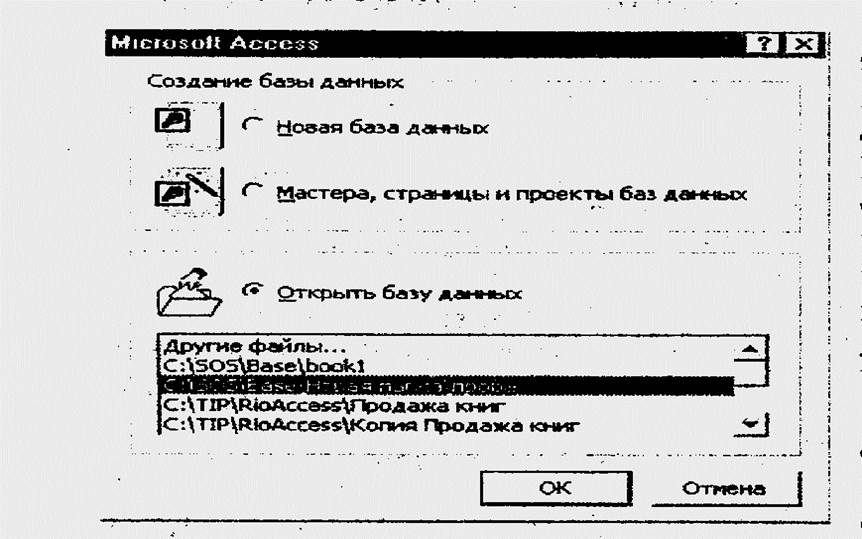
Для создания БД можно воспользоваться Мастером базы данных, установив в окне запуска флажок Мастера, страницы и проекты. Мастер создает БД, содержащую все необходимые объекты, и остается только ввести в таблицы данные. Это простейший способ начального создания БД, но в этом случае придется пользоваться шаблоном, предлагающим определенную структуру БД. Мастера баз данных нельзя использовать для добавления новых таблиц, форм, отчетов в уже существующую БД.
Флажок Открыть базу данных окна запуска позволяет открыть ранее
созданную БД, выбрав ее имя из предлагаемого списка. При выборе Другие файлы предоставляется каталог, из которого можно открыть нужную БД.
- АлтГТУ 419
- АлтГУ 113
- АмПГУ 296
- АГТУ 266
- БИТТУ 794
- БГТУ «Военмех» 1191
- БГМУ 172
- БГТУ 602
- БГУ 153
- БГУИР 391
- БелГУТ 4908
- БГЭУ 962
- БНТУ 1070
- БТЭУ ПК 689
- БрГУ 179
- ВНТУ 119
- ВГУЭС 426
- ВлГУ 645
- ВМедА 611
- ВолгГТУ 235
- ВНУ им. Даля 166
- ВЗФЭИ 245
- ВятГСХА 101
- ВятГГУ 139
- ВятГУ 559
- ГГДСК 171
- ГомГМК 501
- ГГМУ 1967
- ГГТУ им. Сухого 4467
- ГГУ им. Скорины 1590
- ГМА им. Макарова 300
- ДГПУ 159
- ДальГАУ 279
- ДВГГУ 134
- ДВГМУ 409
- ДВГТУ 936
- ДВГУПС 305
- ДВФУ 949
- ДонГТУ 497
- ДИТМ МНТУ 109
- ИвГМА 488
- ИГХТУ 130
- ИжГТУ 143
- КемГППК 171
- КемГУ 507
- КГМТУ 269
- КировАТ 147
- КГКСЭП 407
- КГТА им. Дегтярева 174
- КнАГТУ 2909
- КрасГАУ 370
- КрасГМУ 630
- КГПУ им. Астафьева 133
- КГТУ (СФУ) 567
- КГТЭИ (СФУ) 112
- КПК №2 177
- КубГТУ 139
- КубГУ 107
- КузГПА 182
- КузГТУ 789
- МГТУ им. Носова 367
- МГЭУ им. Сахарова 232
- МГЭК 249
- МГПУ 165
- МАИ 144
- МАДИ 151
- МГИУ 1179
- МГОУ 121
- МГСУ 330
- МГУ 273
- МГУКИ 101
- МГУПИ 225
- МГУПС (МИИТ) 636
- МГУТУ 122
- МТУСИ 179
- ХАИ 656
- ТПУ 454
- НИУ МЭИ 641
- НМСУ «Горный» 1701
- ХПИ 1534
- НТУУ «КПИ» 212
- НУК им. Макарова 542
- НВ 777
- НГАВТ 362
- НГАУ 411
- НГАСУ 817
- НГМУ 665
- НГПУ 214
- НГТУ 4610
- НГУ 1992
- НГУЭУ 499
- НИИ 201
- ОмГТУ 301
- ОмГУПС 230
- СПбПК №4 115
- ПГУПС 2489
- ПГПУ им. Короленко 296
- ПНТУ им. Кондратюка 119
- РАНХиГС 186
- РОАТ МИИТ 608
- РТА 243
- РГГМУ 118
- РГПУ им. Герцена 124
- РГППУ 142
- РГСУ 162
- «МАТИ» — РГТУ 121
- РГУНиГ 260
- РЭУ им. Плеханова 122
- РГАТУ им. Соловьёва 219
- РязГМУ 125
- РГРТУ 666
- СамГТУ 130
- СПбГАСУ 318
- ИНЖЭКОН 328
- СПбГИПСР 136
- СПбГЛТУ им. Кирова 227
- СПбГМТУ 143
- СПбГПМУ 147
- СПбГПУ 1598
- СПбГТИ (ТУ) 292
- СПбГТУРП 235
- СПбГУ 582
- ГУАП 524
- СПбГУНиПТ 291
- СПбГУПТД 438
- СПбГУСЭ 226
- СПбГУТ 193
- СПГУТД 151
- СПбГУЭФ 145
- СПбГЭТУ «ЛЭТИ» 380
- ПИМаш 247
- НИУ ИТМО 531
- СГТУ им. Гагарина 114
- СахГУ 278
- СЗТУ 484
- СибАГС 249
- СибГАУ 462
- СибГИУ 1655
- СибГТУ 946
- СГУПС 1513
- СибГУТИ 2083
- СибУПК 377
- СФУ 2423
- СНАУ 567
- СумГУ 768
- ТРТУ 149
- ТОГУ 551
- ТГЭУ 325
- ТГУ (Томск) 276
- ТГПУ 181
- ТулГУ 553
- УкрГАЖТ 234
- УлГТУ 536
- УИПКПРО 123
- УрГПУ 195
- УГТУ-УПИ 758
- УГНТУ 570
- УГТУ 134
- ХГАЭП 138
- ХГАФК 110
- ХНАГХ 407
- ХНУВД 512
- ХНУ им. Каразина 305
- ХНУРЭ 324
- ХНЭУ 495
- ЦПУ 157
- ЧитГУ 220
- ЮУрГУ 306
Полный список ВУЗов
Чтобы распечатать файл, скачайте его (в формате Word).
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
Определение сущностей
На этом этапе вам необходимо определить сущности, из которых будет состоять база данных.
Сущность — это объект в базе данных, в котором хранятся данные. Сущность может представлять собой нечто вещественное (дом, человек, предмет, место) или абстрактное (банковская операция, отдел компании, маршрут автобуса). В физической модели сущность называется таблицей.
Сущности состоят из атрибутов (столбцов таблицы) и записей (строк в таблице).
Обычно базы данных состоят из нескольких основных сущностей, связанных с большим количеством подчиненных сущностей. Основные сущности называются независимыми: они не зависят ни от какой-либо другой сущности. Подчиненные сущности называются зависимыми: для того чтобы существовала одна из них, должна существовать связанная с ней основная таблица.
На диаграммах сущности обычно представляются в виде прямоугольников. Имя сущности указывается внутри прямоугольника:
Любая таблица имеет следующие характеристики:
- в ней нет одинаковых строк;
- все столбцы (атрибуты) в таблице должны иметь разные имена;
- элементы в пределах одной колонки имеют одинаковый тип (строка, число, дата);
- порядок следования строк в таблице может быть произвольным.
На этом этапе вам необходимо выявить все категории информации (сущности), которые будут храниться в базе данных.
8 ответов
Лучший ответ
Я бы использовал составной (многоколоночный) ключ.
Таким образом, вы можете использовать t1ID и t2ID в качестве внешних ключей, указывающих на соответствующие таблицы.
378
AlexCuse
29 Апр 2011 в 18:47
Предположим, вы уже создали таблицу, теперь вы можете использовать этот запрос для создания составного первичного ключа.
11
Rob
23 Авг 2017 в 06:19
Синтаксис: , например:
Приведенный выше пример будет работать, если вы пишете его во время создания таблицы, например:
Чтобы добавить это ограничение в существующую таблицу, вам необходимо следовать следующему синтаксису
17
Ritabrata Gautam
8 Май 2014 в 16:07
Я бы не стал делать первичный ключ таблицы «info» составной частью двух значений из других таблиц.
Другие могут лучше сформулировать причины, но кажется неправильным иметь столбец, который на самом деле состоит из двух частей. Что, если вы по какой-то причине хотите отсортировать ID из второй таблицы? Что, если вы хотите подсчитать, сколько раз присутствует значение из любой таблицы?
Я бы всегда держал их как две отдельные колонки. Вы можете использовать первичный ключ с двумя столбцами в mysql … PRIMARY KEY (id_a, id_b) … но я предпочитаю использовать уникальный индекс с двумя столбцами и иметь поле первичного ключа с автоинкрементом.
22
wmorse
29 Апр 2011 в 19:27
@AlexCuse Я хотел добавить это в качестве комментария к вашему ответу, но сдался после нескольких неудачных попыток добавить новые строки в комментарии.
Тем не менее, t1ID уникален в table_1, но это не делает его уникальным и в таблице INFO.
Например:
Таблица_1 содержит: Поле идентификатора 1 А 2 млрд
Таблица_2 содержит: Поле идентификатора 1 х 2 года
INFO может иметь: t1ID поле t2ID 1 1 немного 1 2 данные 2 по 1 штуке 2 2 ряд
Итак, в таблице INFO для однозначной идентификации строки вам нужны как t1ID, так и t2ID
1
sactiw
5 Июн 2014 в 13:45
1
Matt Fenwick
18 Апр 2012 в 14:49
Составные первичные ключи — это то, что вам нужно, когда вы хотите создать связь «многие ко многим» с таблицей фактов. Например, у вас может быть пакет аренды на время отпуска, который включает в себя несколько объектов недвижимости. С другой стороны, недвижимость также может быть доступна как часть ряда пакетов аренды, как отдельно, так и вместе с другими объектами недвижимости. В этом сценарии вы устанавливаете связь между собственностью и арендным пакетом с помощью таблицы фактов собственности / пакета. Связь между свойством и пакетом будет уникальной, вы будете только когда-либо присоединяться, используя property_id с таблицей свойств и / или package_id с таблицей пакетов. Каждое отношение уникально, а ключ auto_increment является избыточным, так как он не будет присутствовать ни в одной другой таблице. Следовательно, определение составного ключа — это ответ.
4
Adam Penny
12 Мар 2013 в 18:43
Помимо личных предпочтений в дизайне, бывают случаи, когда нужно использовать составные первичные ключи. Таблицы могут иметь два или более полей, которые обеспечивают уникальную комбинацию, и не обязательно посредством внешних ключей.
Например, в каждом штате США есть набор уникальных избирательных округов. Хотя во многих штатах может быть индивидуально CD-5, никогда не будет больше одного CD-5 в любом из 50 штатов, и наоборот. Следовательно, создание поля автонумерации для Massachusetts CD-5 было бы излишним.
Если база данных управляет динамической веб-страницей, написание кода для запроса по комбинации из двух полей может быть намного проще, чем извлечение / повторная отправка автоматически пронумерованного ключа.
Так что, хотя я не отвечаю на исходный вопрос, я, безусловно, ценю прямой ответ Адама.
5
KiloVoltaire
17 Окт 2013 в 11:15
1.2.5. Первичный ключ
Мы уже достаточно много говорили про ключевые поля, но ни разу их не использовали. Самое интересное, что все работало. Это преимущество, а может недостаток базы данных Microsoft SQL Server и MS Access. В таблицах Paradox такой трюк не пройдет и без наличия ключевого поля таблица будет доступна только для чтения.
В какой-то степени ключи являются ограничениями, и их можно было рассматривать вместе с оператором CHECK, потому что объявление происходит схожим образом и даже используется оператор CONSTRAINT. Давайте посмотрим на этот процесс на примере. Для этого создадим таблицу из двух полей «guid» и «vcName». При этом поле «guid» устанавливается как первичный ключ:
CREATE TABLE Globally_Unique_Data ( guid uniqueidentifier DEFAULT NEWID(), vcName varchar(50), CONSTRAINT PK_guid PRIMARY KEY (Guid) )
Самое вкусное здесь это строка CONSTRAINT. Как мы знаем, после этого ключевого слова идет название ограничения, и объявления ключа не является исключением. Для именования первичного ключа, я рекомендую использовать именование типа PK_имя, где имя – это имя поля, которое должно стать главным ключом. Сокращение PK происходит от Primary Key (первичный ключ).
После этого, вместо ключевого слова CHECK, которое мы использовали в ограничениях, стоит оператор PRIMARY KEY, Именно это указывает на то, что нам необходима не проверка, а первичный ключ. В скобках указывается одно, или несколько полей, которые будут составлять ключ.
Помните, что в ключевом поле не может быть одинакового значения у двух строк, в этом ограничение первичного ключа идентично ограничению уникальности. Это значит, что если сделать поле для хранения фамилии первичным ключом, то в такую таблицу нельзя будет записать двух Ивановых с разными именами. Это нарушает ограничение первичного ключа. Именно поэтому ключи являются ограничениями и объявляются также как и ограничение CHECK. Но это не верно только для первичных ключей и вторичных с уникальностью.
В данном примере, в качестве первичного ключа выступает поле типа uniqueidentifier (GUID). Значение по умолчанию для этого поля – результат выполнения серверной процедуры NEWID.
Внимание
Только один первичный ключ может быть создан для таблицы
Для простоты примеров, в качестве ключа желательно использовать численный тип и если позволяет база данных, то будет лучше, если он будет типа «autoincrement» (автоматически увеличивающееся/уменьшающееся число). В MS SQL Server таким полем является IDENTITY, а в MS Access это поле типа «счетчик».
Следующий пример показывает, как создать таблицу товаров, в которой в качестве первичного ключа выступает целочисленное поле с автоматическим увеличением:
CREATE TABLE Товары ( id int IDENTITY(1, 1), товар varchar(50), Цена money, Количество numeric(10, 2), CONSTRAINT PK_id PRIMARY KEY (id) )
Именно такой тип ключа мы будем использовать чаще всего, потому что в ключевом поле будут храниться легкие для восприятия числа и с ними проще и нагляднее работать.
Первичный ключ может состоять из более, чем одной колонки. Следующий пример создает таблицу, в которой поля «id» и «Товар» образуют первичный ключ, а значит, будет создан индекс уникальности на оба поля:
CREATE TABLE Товары1
(
id int IDENTITY(1, 1),
Товар varchar(50),
Цена money,
Количество numeric(10, 2),
CONSTRAINT PK_id PRIMARY KEY
(id, )
)
Очень часто программисты создают базу данных с ключевым полем в виде целого числа, но при этом в задаче четко стоит, что определенные поля должны быть уникальными. А почему не создать сразу первичный ключ из тех полей, которые должны быть уникальны и не надо будет создавать отдельные решения для данной проблемы.
Единственный недостаток первичного ключа из нескольких колонок – проблемы создания связей. Тут приходиться выкручиваться различными методами, но проблема все же решаема. Достаточно только ввести поле типа uniqueidentifier и производить связь по нему. Да, в этом случае у нас получаются уникальными первичный ключ и поле типа uniqueidentifier, но эта избыточность в результате не будет больше, чем та же таблица, где первичный ключ uniqueidentifier, а на поля, которые должны быть уникальными установлено ограничение уникальности. Что выбрать? Зависит от конкретной задачи и от того, с чем вам удобнее работать.
Ключи
Последнее обновление: 02.07.2017
Ключи представляют способ идентификации строк в таблице. С помощью ключей мы также можем связывать строки между различными таблицами в отношения.
Суперключ
Superkey (суперключ) — комбинация атрибутов (столбцов), которые уникально идентифицируют каждую строку таблицы. Это могут быть и все столбцы, и
несколько и и один. При этом строки, которые содержат значения этих атрибутов, не должны повторяться.
Например, у нас есть сущность Student, которая представляет данные о пользователях и которая имеет следующие атрибуты:
-
FirstName (имя)
-
LastName (фамилия)
-
Year (год рождения)
-
Phone (номер телефона)
Какие атрибуты в данном случае могут составлять суперключ:
-
{FirstName, LastName, Year, Phone}
-
{FirstName, Year, Phone}
-
{LastName, Year, Phone}
-
{FirstName, Phone}
-
{LastName, Phone}
-
{Year, Phone}
-
{Phone}
Каждого студента уникально может идентифицировать телефонный номер, поэтому любые наборы, в которых встречается атрибут Phone, представляют суперключ.
А вот, к примеру, набор не является суперключом, так как у нас теоретически могут быть как минимум
два студента с одинаковыми именем, фамилией и годом рождения.
Потенциальный ключ
Candidate key (потенциальный ключ) — представляет собой минимальный суперключ отношения (таблицы), то есть набор атрибутов, который удовлетворяет ряду условий:
-
Неприводимость: он не может быть сокращен, он содержит минимально возможный набор атрибутов
-
Уникальность: он должен иметь уникальные значения вне зависимости от изменения строки
-
Наличие значения: он не должен иметь значения NULL, то есть он обязательно должен иметь значение.
Возьмем ранее выделенные суперключи и найдем среди них candidate key. Первый пять суперключей не соответствуют первому условию, так как все их можно сократить до суперключа {Phone}:
-
{FirstName, LastName, Year, Phone}
-
{FirstName, Year, Phone}
-
{LastName, Year, Phone}
-
{FirstName, Phone}
-
{LastName, Phone}
-
{Year, Phone}
Суперключ {Phone} соответствует первому и второму условию, так как он имеет уникальное значение (в данном случае все пользователи могут иметь только уникальные телефонные номера). Но соответствует ли он третьему условию?
В целом нет, так как теоретически студент может и не иметь телефона. В этом случае атрибут Phone будет иметь значение NULL, то есть значение
будет отсутствовать.
В то же время это может зависеть от ситуации. Если в какой-то систему номер телефона является неотъемлемым атрибутом, например, используется для регистрации и входа в систему, то его можно считать потенциальным ключом. Но
в данном случае мы рассматриваем общую ситуацию. И для понимания потенциального ключа необходимо отталкиваться от конкретной системы, которую описывает база данных.
И в таком случае суперключи таблицы не содержат потенциального ключа.
Первичный ключ
Первичный ключ (primary key) непосредственно применяется для идентификации строк в таблице. Он должен соответствовать следующим ограничениям:
-
Первичный ключ должен быть уникальным все время
-
Он должен постоянно присутствовать в таблице и иметь значение
-
Он не должен часто менять свое значение. В идеале он вообще не должен изменять значение.
Как правило, первичный ключ представляет один столбец таблицы, но также может быть составным и состоять из нескольких столбцов.
Если для таблицы можно выделить потенциальный ключ, то его можно использовать в качестве первичного ключа.
Если же потенциальные ключи отсутствуют, то для первичного ключа можно добавить к сущности специальный атрибут, который, как правило, называется, Id или
имеет форму Id (например, StudentId), либо может иметь другое название. И обычно данный атрибут принимает целочисленное значение, начиная с 1.
Если же у нас есть несколько потенциальных ключей, то те потенциальные ключи, которые не составляют первичный ключ, являются альтернативными ключами
(alternative key).
Например, возьмем представление пользователей на сайтах с двухфакторной авторизацией, где нам обязательно иметь электронный адрес, который нередко выступает в качестве
логина, и какой-нибудь номер телефона. В этом случае таблицу пользователей мы можем задать с помощью следующих атрибутов:
-
Name (имя пользователя)
-
Password (пароль)
-
Phone (телефонный номер)
НазадВперед






