Руководство по разработке структуры и проектированию базы данных
Содержание:
- Добавление индексов и представлений
- Сценарий 2. Разобраться с устройством механизма или подсистемы
- Шаг 2. Избавляемся от дубликатов в столбцах
- Сценарий 1. Какие объекты конфигурации использует данный объект
- Отношения между таблицами
- Создание базы данных с помощью шаблона
- Зачем в 1С:Предприятии понадобилась ER-модель
- Создаем базу данных
- Создание базы данных
- Создание базы данных в MS Access 2010
Добавление индексов и представлений
Индекс — это отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет быстрее находить записи. Вместо повторной сортировки для каждого запроса система может обращаться к записям в порядке, указанном индексом.
Хотя индексы ускоряют извлечение данных, они могут замедлять добавление, обновление и удаление данных, поскольку индекс нужно перестраивать всякий раз, когда изменяется запись.
Представление — это сохраненный запрос данных. Представления могут включать в себя данные из нескольких таблиц или отображать часть таблицы.
Сценарий 2. Разобраться с устройством механизма или подсистемы
Второй сценарий заключается в том, что вам нужно разобраться с устройством незнакомого механизма или подсистемы. Например, нужно понять, как устроена подсистема ТоварныеЗапасы. Какие объекты в ней задействованы и как они связаны друг с другом.
В этом случае, как и в первом сценарии, вы можете открыть редактор этой подсистемы и перейти на закладку Схема данных. Здесь вы увидите более интересную картину, потому что кроме объектов на этой схеме будут показаны и подчинённые подсистемы.
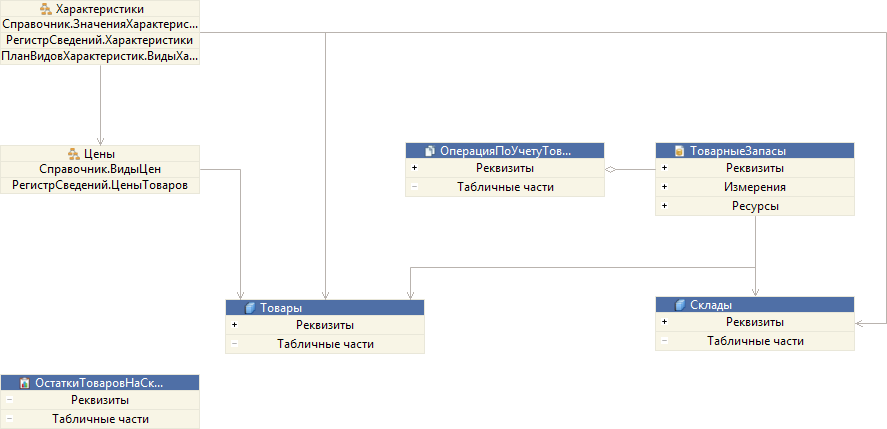
Подсистемы являются группами объектов. Содержащиеся в них объекты имеют связи с объектами, которые находятся «снаружи». Чтобы посмотреть, как устроена любая из этих подсистем, например подсистема Характеристики, вы можете кликнуть на ней прямо в схеме, и увидите её устройство.
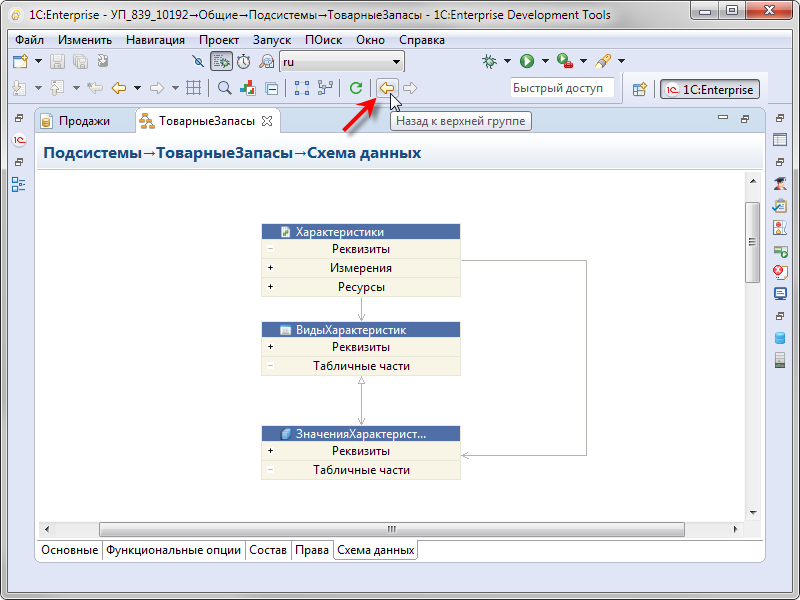
Интересным моментом является то, что схема данных поддерживает переходы Вперед / Назад по аналогии с браузерами. Поэтому, разобравшись с устройством этой подчинённой подсистемы, вы можете просто нажать кнопку Назад, и вернуться к предыдущей схеме.
Шаг 2. Избавляемся от дубликатов в столбцах
Как было оговорено выше, столбцы “username” и “following_username” содержат дубликаты данных. Они возникли в результате того, что я хотел отобразить отношения между твиттами и пользователями. Давайте улучшим нашу структуру БД, разделив существующую таблицу на две: в одной будем хранить информацию, а в другой — отношения между записями.
Поскольку @Brett_Englebert подписан на @RealSkipBayless, то в таблице “following” отобразим это следующим образом: имя @Brett_Englebert поместим в колонку “from_user”, а @RealSkipBayless в “to_user.” Давайте посмотрим, как будет выглядеть таблица “following” после разделения Таблицы 1:
Таблица 2. following
| from_user | to_user |
|---|---|
| _DreamLead | Scootmedia |
| _DreamLead | MetiersInternet |
| GunnarSvalander | klout |
| GunnarSvalander | zillow |
| GEsoftware | DayJobDoc |
| GEsoftware | byosko |
| adrianburch | CindyCrawford |
| adrianburch | Arjantim |
| AndyRyder | MichaelDell |
| AndyRyder | Yahoo |
| Brett_Englebert | RealSkipBayless |
| Brett_Englebert | stephenasmith |
| NimbusData | dellock6 |
| NimbusData | rohitkilam |
| SSWUGorg | drsql |
| SSWUGorg | steam_games |
Таблица 3. users
| full_name | username | text | created_at |
|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Уже лучше. Теперь в таблице “users” (Таблица 3) у нас хранится только информация о твиттах, а в таблице following (Таблица 2) — зависимость пользователей.
Основатель теории реляционных баз данных, Эдгар Кодд, назвал бы этот процесс (удаления повторений из столбцов таблиц) приведением БД к первой нормальной форме.
Сценарий 1. Какие объекты конфигурации использует данный объект
Это самый простой сценарий. Например, у вас есть регистр Продажи. Вам нужно узнать, какие объекты конфигурации использует это регистр. То есть, на какие объекты конфигурации ссылаются его реквизиты, измерения и ресурсы.
Раньше для этого вы раскрыли бы его структуру в дереве объектов конфигурации и вручную смотрели бы типы реквизитов в палитре свойств. Если регистр большой, то, возможно, вы использовали бы команду Поиск ссылок в объекте. После этого каким-то образом вам нужно было записать то, что вы нашли.
Теперь эта задача решается значительно проще. Вы открываете редактор объекта конфигурации и переходите на закладку Схема данных. Такая закладка есть у всех прикладных объектов конфигурации.
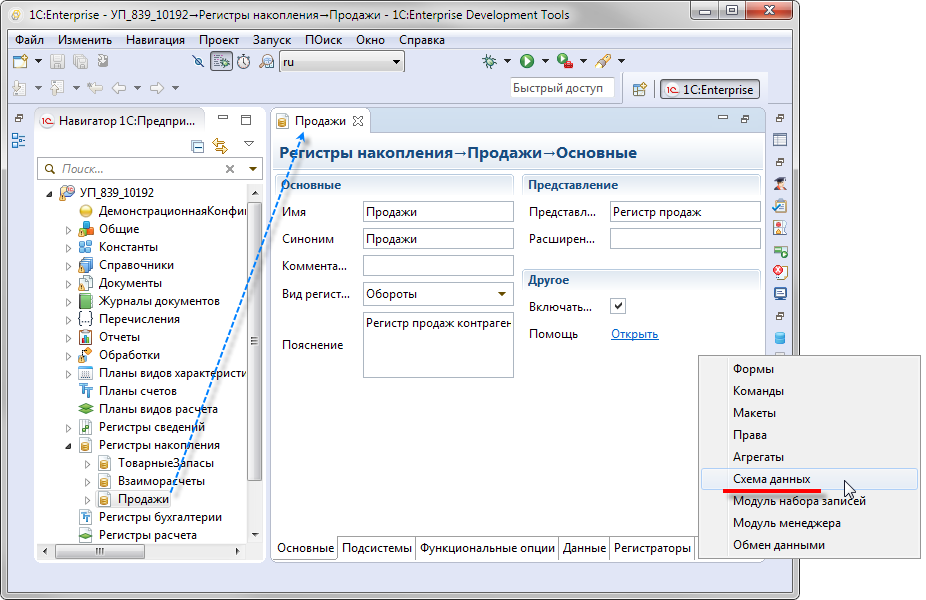
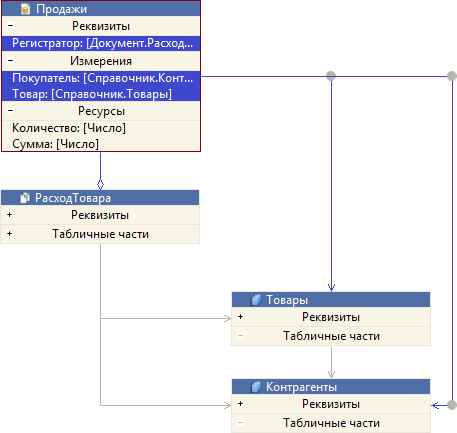
EDT сразу же показывает вам ER-диаграмму. В неё включаются все объекты первого уровня, которые использует регистр Продажи.
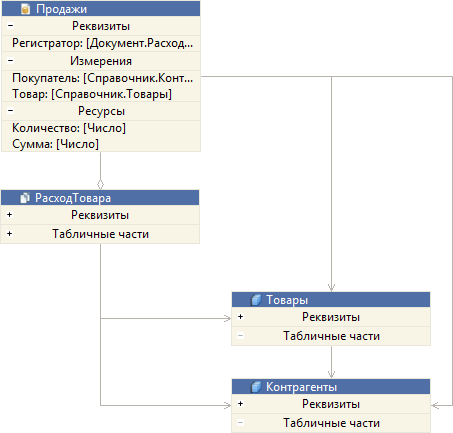
На этой схеме данных видно, что регистр Продажи использует документ РасходТовара и справочники Товары и Контрагенты. Эти связи исходят из регистра. Кроме этого на схеме показаны и взаимные связи между самими используемыми объектами (между документом и справочниками).
Вообще говоря, связей может быть много. Чтобы легче ориентироваться в них вы можете выделить мышью исследуемый объект, и тогда исходящие из него связи будут подсвечены. Также будут подсвечены и реквизиты объекта, задействованные в этих связях.
Если вас интересует только одна связь, вы можете нажать на неё, и тогда будет подсвечена она и реквизит, связанный с ней.
Обычно связи обозначаются открытой стрелкой, но для некоторых связей мы используем специальные обозначения: закрытая стрелка и ромб. Например, другая схема данных может выглядеть так:
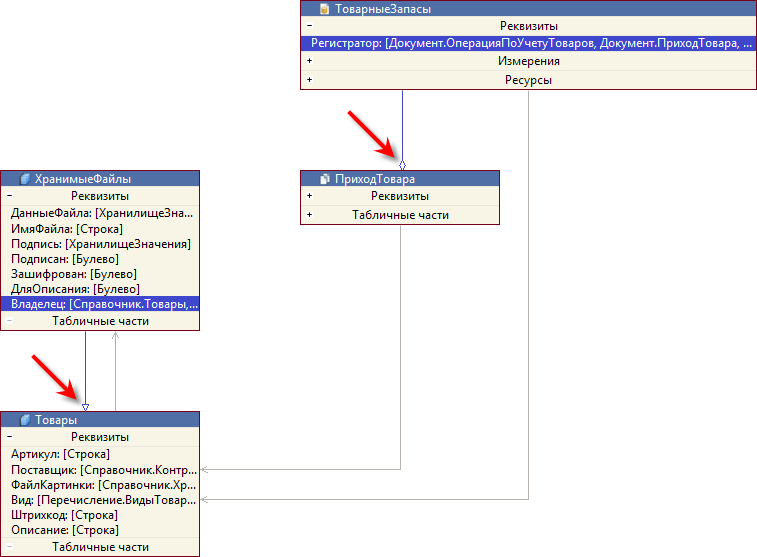
Закрытой стрелкой обозначается связь с владельцем, а ромбом – с регистратором. Это помогает визуально отличать «техногенные» связи от прикладных.
Такую схему данных, которая открывается на закладке редактора объекта конфигурации, вы можете изменять и модифицировать: раскрывать группы реквизитов, перетаскивать объекты, располагая их более удобным образом, и т.д.
Но нужно учитывать, что эти изменения не сохраняются в конфигурации. Ту схему, которую вы видите, вы можете сохранить как картинку или напечатать (всю схему, или только её часть). Но в следующий раз, когда вы откроете редактор объекта конфигурации и перейдёте на закладку Схема данных, схема будет нарисована заново в стандартном виде.
Поэтому здесь, в этом месте, не нужно увлекаться наведением «красоты», для этого есть другой сценарий, который мы тоже рассмотрим далее.
Отношения между таблицами
Чтобы база данных стала реляционной, одних данных мало. Между ними нужны еще и связи (те самые relations, от которых и пошло слово «реляционный»).
Для связи между таблицами служит так называемый внешний ключ (foreign key). Название довольно точно выражает его суть. Если в таблице A есть столбец для хранения первичного ключа таблицы B, то такой столбец и называется внешним ключом. Первичные и внешние ключи устанавливают связи между таблицами, превращая набор таблиц в цельную конструкцию — реляционную базу данных.
Приведу пример. Допустим, мы создали еще одну простую таблицу — справочник товаров. Назовем ее GOODS.
| Товарный справочник GOODS | ||||
| ID | NAME | PRICE | UNIT | COUNTRY |
| 1 | Яблоки | 50.00 | кг | Россия |
| 2 | Груши | 60.40 | кг | Франция |
| 3 | Апельсины | 40.00 | кг | Марокко |
| 4 | Макароны | 21.00 | шт | Франция |
| 5 | Кефир | 25.30 | шт | Россия |
| 6 | Молоко | 30.50 | шт | Россия |
Ее колонки: ID — первичный ключ, NAME — название товара, PRICE — его цена, UNIT — краткое название единицы измерения, COUNTRY — название страны-производителя.
Хорошо ли построена такая таблица? Вроде бы всем упоминавшимся выше принципам она удовлетворяет: уникальные имена столбцов с однородными данными, строки с уникальным первичным ключом. Казалось бы, все на месте. Тем не менее построена она непрофессионально. Здесь мы подходим к принципам, о которых я еще не упоминал, — к понятию о нормализации таблиц. Суть в том, чтобы всюду, где только можно, избегать избыточности в хранении данных путем выделения их в отдельные таблицы.
Посмотрим на нашу таблицу GOODS. Чем она плоха? Представьте себе, что завтра придется изменить название какой-нибудь страны. Такое случается часто. Бирма когда-то меняла свое название на Мьянму, Польша — на Польскую Республику. Хочется ли вам менять огромное количество строк во всех таблицах, где эти страны упоминаются? Представьте также, что вас попросят отобрать запросом весь штучный товар. Можете ли вы быть уверены в том, что оператор всюду набил эту аббревиатуру правильно и одинаково? Скорее всего, окажется, что в таблице встречаются все мыслимые вариации: «шт», «Шт», «шт.», «штук» и «штуки».
Думаю, проблема понятна. Выходом из этой ситуации будет выделение из нее двух других таблиц: справочника стран (COUNTRIES) и справочника единиц измерений (UNITS).
| Справочник единиц измерения UNITS | ||
| ID | NAME | SHORT_NAME |
| 1 | Штуки | шт |
| 2 | Килограммы | кг |
Сам справочник товаров GOODS будет теперь выглядеть совершенно по-другому (см. таблицу).
| Товарный справочник GOODS после нормализации | ||||
| ID | NAME | PRICE | UNIT_ID | COUNTRY_ID |
| 1 | Яблоки | 50.00 | 2 | 1 |
| 2 | Груши | 60.40 | 2 | 2 |
| 3 | Апельсины | 40.00 | 2 | 3 |
| 4 | Макароны | 21.00 | 1 | 2 |
| 5 | Кефир | 25.30 | 1 | 1 |
| 6 | Молоко | 30.50 | 1 | 1 |
Что изменилось? Вместо столбцов с названиями единиц измерения и стран появились столбцы UNIT_ID и COUNTRY_ID с кодами, отсылающими нас к другим таблицам. Это и есть внешние ключи. Что означает значение 2 в столбце UNIT_ID? Оно означает, что интересующая нас информация по единице измерения находится той строке таблицы UNITS, где ID = 2. Достаточно заглянуть в этот справочник, чтобы убедиться, что называется эта единица полностью «штуки», а кратко — «шт».
Объяснение всех видов и принципов нормализации выходит далеко за рамки данной статьи. Главное — почувствовать общие принципы. Единожды научившись строить базы данных правильно, вы уже не сможете иначе. Для этого не обязательно знать теорию в полном объеме — зачастую здравого смысла и интуиции бывает достаточно.
Вернемся к нашей маленькой базе данных. Ну хорошо, нормализовали мы таблицу. Сможем теперь менять названия стран, не исправляя всю таблицу. Замечательно. Но как теперь увидеть эти названия? Ведь в справочнике товаров появились коды, и таблица сразу потеряла свою наглядность.
Вот тут-то мы и подходим к понятию уже не раз упоминавшихся запросов, которые, используя связи, извлекают из них нужную информацию и выдают нам опять же в виде так называемой отчетной таблицы.
Создание базы данных с помощью шаблона
В Access есть разнообразные шаблоны, которые можно использовать как есть или в качестве отправной точки. Шаблон — это готовая к использованию база данных, содержащая все таблицы, запросы, формы, макросы и отчеты, необходимые для выполнения определенной задачи. Например, существуют шаблоны, которые можно использовать для отслеживания вопросов, управления контактами или учета расходов. Некоторые шаблоны содержат примеры записей, демонстрирующие их использование.
Если один из этих шаблонов вам подходит, с его помощью обычно проще и быстрее всего создать необходимую базу данных. Однако если необходимо импортировать в Access данные из другой программы, возможно, будет проще создать базу данных без использования шаблона. Так как в шаблонах уже определена структура данных, на изменение существующих данных в соответствии с этой структурой может потребоваться много времени.
-
Если база данных открыта, нажмите на вкладке Файл кнопку Закрыть. В представлении Backstage откроется вкладка Создать.
-
На вкладке Создать доступно несколько наборов шаблонов. Некоторые из них встроены в Access, а другие шаблоны можно скачать с сайта Office.com. Дополнительные сведения см. в следующем разделе.
-
Выберите шаблон, который вы хотите использовать.
-
Access предложит имя файла для базы данных в поле «Имя файла». При этом имя файла можно изменить. Чтобы сохранить базу данных в другой папке, отличной от папки, которая отображается под полем «Имя файла», нажмите кнопку , перейдите к папке, в которой ее нужно сохранить, и нажмите кнопку «ОК». При желании вы можете создать базу данных и связать ее с сайтом SharePoint.
-
Нажмите кнопку Создать.
Access создаст базу данных на основе выбранного шаблона, а затем откроет ее. Для многих шаблонов при этом отображается форма, в которую можно начать вводить данные. Если шаблон содержит примеры данных, вы можете удалить каждую из этих записей, щелкнув область маркировки (затененное поле или полосу слева от записи) и выполнив действия, указанные ниже.
На вкладке Главная в группе Записи нажмите кнопку Удалить.
-
Щелкните первую пустую ячейку в форме и приступайте к вводу данных. Для открытия других необходимых форм или отчетов используйте область навигации. Некоторые шаблоны содержат форму навигации, которая позволяет перемещаться между разными объектами базы данных.
Дополнительные сведения о работе с шаблонами см. в статье Создание базы данных Access на компьютере с помощью шаблона.
Зачем в 1С:Предприятии понадобилась ER-модель
Необходимость использования этой модели данных в 1С:Предприятии прямо связана с ростом платформы и значительным усложнением прикладных решений. По этой же причине мы реализовали схему данных в составе новой среды разработки EDT, которая ориентирована именно на большие конфигурации.
Если посмотреть на любую базу данных 1С:Предприятия то вы увидите, что она основана на реляционной модели. Грубо говоря, она состоит из таблиц, которые связаны между собой различными способами. Таблицы имеют поля, из этих полей формируются ключи, которые позволяют связывать таблицы друг с другом.
Такая модель удобна для компьютерной обработки, но неудобна для визуального представления разработчику. Особенно неудобна она в случае 1С:Предприятия, где большинство таблиц имеет не абстрактное, а совершенно конкретное прикладное значение.
Поэтому исторически в конфигураторе 1С:Предприятия используется другая концептуальная модель, представляющая базу данных в виде дерева объектов конфигурации. Объекты конфигурации скрывают за собой реляционную модель, они сгруппированы по принадлежности к тому или иному классу прикладных задач. Такое представление удобно для быстрого нахождения нужных объектов, изменения их свойств и т.д. Однако это представление не даёт простого и наглядного понятия о взаимной связи разных объектов между собой.
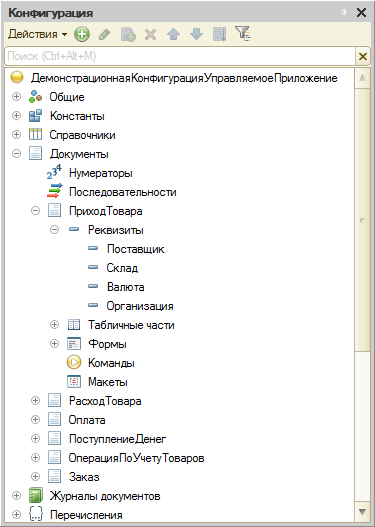
Современные прикладные решения 1С:Предприятия содержат большое количество объектов конфигурации, 10 тысяч и более. При таком количестве объектов задача нахождения их взаимных связей с помощью имеющихся инструментов становится довольно трудоёмкой. Причём трудоёмкость растёт не только за счёт прямого увеличения времени поиска ссылок среди большого количества объектов. Она растёт и косвенно, за счёт того, что найденные связи необходимо как-то запомнить и визуализировать. И если таких связей много, встаёт вопрос выбора подходящего внешнего инструмента.
Использование ER-модели (Entity-Relationship Model) как раз решает эту проблему. ER-модель представляет любую структуру данных в виде совокупности сущностей, обладающих атрибутами. Эти сущности взаимодействуют между собой при помощи связей.
В наших терминах, в терминах 1С:Предприятия, сущность это объект конфигурации, а атрибут это реквизит объекта конфигурации в широком смысле: реквизит, измерение, ресурс и т.д. Таким образом, ER-модель базы данных 1С:Предприятия это набор (никак не структурированный) объектов конфигурации (с их реквизитами), между которыми существуют некоторые связи. А схема данных это инструмент, позволяющий визуализировать эту модель.
Всё это теоретическое отступление мы написали только ради того, чтобы обратить ваше внимание на две важные вещи.
Во-первых, схема данных это не что-то опциональное, это не «бантик», добавляющий привлекательности среде разработки. Это вполне себе самостоятельный инструмент моделирования предметной области, обладающий своими преимуществами и особенностями.
Во-вторых, схема данных это не аналог и не замена дерева объектов конфигурации. Это ещё один инструмент разработки, но он, можно сказать, имеет свою собственную аудиторию.
Дерево объектов конфигурации в большей степени удобно для разработчиков, глубоко погруженных в прикладное решение, или знакомых с его генезисом. Оно позволяет быстро модифицировать приложение, при этом большую часть информации о взаимной связи объектов разработчик прекрасно знает, и обычно просто держит в голове.
В отличие от дерева объектов схема данных ориентирована скорее на тех разработчиков, которые не знакомы с прикладным решением глубоко, но которым необходимо быстро разобраться в устройстве какой-то его части. Также схема данных удобна для документирования разрабатываемых механизмов (в том числе и самими разработчиками), поскольку в понятном виде показывает связи между объектами или группами объектов.
Дальше, без общих рассуждений, мы просто хотим показать вам несколько практических сценариев использования схемы данных. Они помогут вам не только понять её назначение, но и узнать её возможности.
Создаем базу данных
Управление базами данных как объектами
Будем считать, что наша небольшая экскурсия по запросам и командам SQL со стороны «торгового зала» завершена. Заглянем теперь в его «служебные помещения» и познакомимся с тем, как создается сама база данных. Эта часть языка SQL не столь стандартизирована и сильно отличается в различных реализациях. Поэтому в дальнейших примерах я буду придерживаться синтаксиса, принятого в самой популярной на веб-серверах системе — MySQL.
MySQL — продукт шведской компании MySQL AB. Ее основатели — Дэвид Аксмарк, Аллан Ларсон и Майкл Видениус (последний больше известен по прозвищу — Монти). По одной из версий, первая часть названия продукта (My) — не что иное, как англизированная запись имени дочери М. Видениуса. Однако точно за происхождение названия сегодня не могут поручиться даже отцы-создатели. Существует версия, по которой «my» — это префикс, с которого начинались названия рабочих каталогов на их компьютерах.
Из всех команд чаще всего нам будут нужны три: CREATE (создать), ALTER (изменить) и DROP (уничтожить).
Чтобы создать новую базу данных с названием, ну скажем, OUR_SHOP, следует выполнить команду:
Еще лучше сразу при ее создании установить нужную кодировку (ведь по умолчанию в MySQL используется latin1). В итоге команда будет выглядеть так.
Если вы забыли сделать это сразу, не беда. Для того и существуют команды по изменению:
Когда, наигравшись вдоволь с пробной базой данных, вы захотите ее уничтожить, воспользуйтесь командой:
Управление таблицами
Чтобы создать таблицу GOODS, на которой мы отрабатывали манипуляции с данными, потребуется составить команду примерно такого вида:
Разберем эту команду подробнее. Тип INT устанавливается для столбцов с целочисленными данными, тип VARCHAR(100) обеспечивает хранение строк с длиной не более 100 символов, DECIMAL(10,2) соответствует действительным числам с не более чем десятью знаками и точностью в два знака после запятой.
Столбец ID объявлен первичным ключом (PRIMARY KEY).
Ключевое слово AUTO_INCREMENT означает, что при добавлении новых строк с неуказанным значением ID оно будет автоматически заполняться следующим значением. Это удобно, поскольку обычно нет нужды вручную указывать значения первичных ключей, а за тем, чтобы они были уникальными, пусть лучше следит база данных.
NOT NULL означает запрет на пустые значения в столбце, иными словами, гарантирует обязательность заполнения.
Команда DEFAULT задает значение по умолчанию — то, которое будет записываться в базу при добавлении новой строки, если не указано иное. В нашем случае она обеспечивает автоматическое объявление товара штучным (код = 1) в случае, если при добавлении новых строк не будет указан другой код.
Признак UNIQUE обеспечивает уникальность значений в колонке (в нашем случае — уникальность названий товаров).
Если в будущем вы захотите перенастроить объявленные командой CREATE столбцы таблицы, сделать это можно командой ALTER. Например, таблицу GOODS можно нарастить строчной колонкой REMARK (подкоманда ADD):
Поработав с ней немного и убедившись, что 50 символов для примечания явно недостаточно, увеличиваем максимальный размер строки до 250 (блок CHANGE):
Так как имя столбца мы не изменяли (новое совпадает со старым), то его просто повторяем в этой команде (как бы меняем само на себя).
И наконец, убедившись через какое-то время, что без примечания в товарном справочнике вполне можно обойтись, мы удаляем ставшую ненужной колонку (блок DROP):
Удалить таблицу целиком можно командой DROP:
Стоит ли говорить о том, что пользоваться командами с этим ключевым словом следует с особой осторожностью?
Создание базы данных
Создание новой нормализованной реляционной базы данных Access осуществляется в соответствии с ее структурой, полученной в результате проектирования. Процесс проектирования реляционной базы данных был рассмотрен в предыдущей главе. Структура реляционной базы данных определяется составом таблиц и их взаимосвязями. Взаимосвязи между двумя таблицами реализуются через ключ связи, входящий в состав полей связываемых таблиц. Напомним, что в нормализованной реляционной базе данных таблицы находятся в отношениях типа «один-ко-многим» или «один-к-одному». Для одно-многозначных отношений в качестве ключа связи, как правило, используется уникальный ключ главной таблицы, в подчиненной таблице это может быть любое из полей, которое называется внешним ключом.
Создание реляционной базы данных начинается с формирования структуры таблиц. При этом определяется состав полей, их имена, тип данных каждого поля, размер поля, ключи, индексы таблицы и другие свойства полей. После определения структуры таблиц создается схема данных, в которой устанавливаются связи между таблицами. Access запоминает и использует эти связи при заполнении таблиц и обработке данных.
При создании базы данных важно задать параметры, в соответствии с которыми Access будет автоматически поддерживать целостность данных. Для этого при определении структуры таблиц должны быть заданы ключевые поля таблиц, указаны ограничения на допустимые значения данных, а при создании схемы данных на основе нормализованных таблиц должны быть заданы параметры поддержания целостности связей базы данных
Завершается создание базы данных процедурой загрузки, т. е. заполнением таблиц конкретными данными. Особое значение имеет технология загрузки взаимосвязанных данных. Удобным инструментом загрузки данных во взаимосвязанные таблицы являются формы ввода/вывода, обеспечивающие интерактивный интерфейс для работы с данными базы. Формы позволяют создать экранный аналог документа источника, через который можно вводить данные во взаимосвязанные таблицы.
ВНИМАНИЕ! Пользователь может начинать работу с базой при любом количестве созданных таблиц еще до создания полной базы, отображающей все объекты модели данных предметной области. База данных может создаваться поэтапно, и в любой момент ее можно дополнять новыми таблицами и вводить связи между таблицами в схему данных, существующие таблицы могут дополняться новыми полями
Создание базы данных в MS Access 2010
На открывшейся после запуска Access странице отображено представление Microsoft Office Backstage — набор команд на вкладке Файл (File) — которое предназначено для выполнения команд, применяемых ко всей базе данных. При этом на вкладке Файл (File) выбрана команда Создать (New). Область этой команды содержит Доступные шаблоны (Available Templates), позволяющие создать базу данных с использованием многочисленных шаблонов, размещенных на вашем компьютере или доступных через Интернет.
Шаблон — это готовая к использованию база данных, содержащая все таблицы, запросы, формы и отчеты, необходимые для выполнения определенной задачи. Эти готовые базы данных позволяют быстро создать приложения, ориентированные на поддержку широкого спектра задач. Непрерывно появляются новые шаблоны приложений, которые можно загрузить с веб-узла Microsoft Office Online. Эти стандартные приложения можно использовать без какой-либо модификации и на-стройки либо, взяв их за основу, приспособить шаблон к вашим нуждам и создать новые поля и таблицы, формы, отчеты и другие объекты базы данных. Команда Открыть (Open) предназначена для открытия любой ранее созданной базы данных. Здесь же доступен список из 4 последних открываемых баз данных. Команда Последние (Recent) открывает более длинный список недавно открываемых баз данных. Щелчком на значке кнопки можно добавить базу данных в список последних, а щелчком на значке удалить из списка.
Команда Открыть (Open) предназначена для открытия любой ранее созданной базы данных. Здесь же доступен список из 4 последних открываемых баз данных. Команда Последние (Recent) открывает более длинный список недавно открываемых баз данных.
И у нас видео на эту тему:
Про создание файла базы данных Access читаем в следующей статье.







