Какие бывают базы данных
Содержание:
- Объектно-реляционные субд
- Локальный кэш распределенной информации
- Система управления базами данных (СУБД)
- Реляционная база данных
- NoSQL как альтернатива традиционным БД
- Для чего нужны
- Денормализация
- Ключ-значение
- Представления о преимуществах и недостатках
- Сетевая модель базы данных
- PostgreSQL
- Другие модели баз данных (ООСУБД)
- MEMORY (HEAP)
- Типы баз данных
- Первичные ключи
- Использование среды SQL Server Management Studio
- Бинарные связи
- СУБД
- Добавление индексов и представлений
- Что такое база данных в SQL
- Пример: слежение за почтовыми отправлениями
- Слово, которое вовсе не имеет значения
- Как начать работу с SQL
- А покажите сами запросы
- Коротко главное
- Что дальше
Объектно-реляционные субд
Разница между объектно-реляционными и объектными СУБД: первые являют собой надстройку над реляционной схемой, вторые же изначально объектно-ориентированы. Главная особенность и отличие объектно-реляционных, как и объектных, СУБД от реляционных заключается в том, что О(Р)СУБД интегрированы с Объектно-Ориентированным (OO) языком программирования, внутренним или внешним как C++, Java. Характерные свойства OРСУБД:
- комплексные данные,
- наследование типа,
- объектное поведение.
Комплексные данные могут быть реализованы через постоянно-хранимые объекты (persistent objects). Создание комплексных данных в большинстве существующих ОРСУБД основано на предварительном определении схемы через определяемый пользователем тип (UDT — user-defined type). Используются также встроенные конструкторы составных типов, например массив (ARRAY).
Иерархия структурных комплексных данных предлагает дополнительное свойство, наследование типа. То есть структурный тип может иметь подтипы, которые используют все его атрибуты и содержат дополнительные атрибуты, специфицированные в подтипе.
Объектное поведение закладывается через описание программных объектов. Такие объекты должны быть сохраняемыми и переносимыми для обработки в базе данных, поэтому они называются обычно как постоянные (или долговременные) объекты. Внутри базы данных все отношения с постоянным программным объектом есть отношения с его объектным идентификатором (OID).
Объектно-реляционными СУБД являются, к примеру, широко известные Oracle Database, Microsoft SQL Server 2005, PostgreSQL, а также Sav Zigzag, IBM Cloudscape,
Локальный кэш распределенной информации
В системе слежения за почтовыми отправлениями никогда не требуется доступ ко всей информации сразу. Это обычное явление во всех областях применения: есть вся накопленная и доступная информация, а есть та ее маленькая часть, которая актуальна на конкретный момент времени.
Ничто не мешает веб-ресурсу создать локальный образ распределенной базы данных. Например, пришел посетитель. Еще до того, как он сформулирует запрос, можно подгрузить варианты ответа.
Если есть опыт работы с посетителями из конкретной страны, то может быть известно, из каких стран ожидаются данные.
В некоторых странах система слежения загружена, в основном, локальными запросами (внутри страны), ничто не мешает оптимизировать этот момент, а внешние отправления отдать на откуп другим веб-ресурсам. В некоторых случаях необходимо не только предоставить посетителю внешнюю информацию, но и сопоставить сведения по ответу на один и тот же запрос от разных систем слежения.
Сказать, что в таком случае получится объектно-реляционная модель информации и доступа к ней в определенном смысле возможно, но для реализации этой модели потребуется представить инструмент моделирования действий компаний, работающих в области слежения, то есть развивающих свой функционал.
Система управления базами данных (СУБД)
Система управления базами данных (сокращенно СУБД) – это программное обеспечение для создания и работы с базами данных.
Главная функция СУБД – это управление данными (которые могут быть как во внешней, так и в оперативной памяти). СУБД обязательно поддерживает языки баз данных, а также отвечает за копирование и восстановление информации после каких-либо сбоев.
Реляционные СУБД и язык SQL
Реляционные и объектно-реляционные СУБД являются одними из самых распространенных систем. Они представляют собой таблицы, в которых каждый столбец (он называется «field» или «поле») упорядочен и имеет определенное уникальное название. Последовательность строк (их называют «records» или «записи») определяется последовательностью ввода информации в таблицу. При этом обрабатывание столбцов и строк может происходить в любом порядке. Таблицы с данными связаны между собой специальными отношениями, благодаря чему с данными из разных таблиц можно работать – к примеру, объединять их при помощи одного запроса.
Для управления реляционными базами данных применяется особый язык программирования – SQL. Сокращение расшифровывается как «Structured query language», в переводе на русский – «язык структурированных запросов».
Команды, которые используются в SQL, делятся на:
- манипулирующие данными,
- определяющие данные,
- управляющие данными.
Схема работы с базой данных выглядит следующим образом:

Реляционная база данных
Под данным типом баз данных понимается их представление в рамках двумерной таблицы. Она имеет несколько столбцов, в которых устанавливаются такие параметры, как, например, тип вводимых данных (текст, число, дата и др.).
Таблица здесь является способом хранения введённых в неё данных и способна реагировать на любые обращения со стороны СУБД. Главная проблема в работе с реляционными базами данных состоит в их правильном проектировании.
Во время проектирования базы данных следует учесть следующие два фактора:
- база данных должна быть компактной и не содержать избыточных компонентов;
- обработка базы данных должны происходить просто.
Проблема в том, что эти факторы друг другу противоречат. А ведь проектирование — важнейший момент при составлении базы данных и дальнейшей работе с ней. Заниматься им рекомендуется администратору сервера, обладающему определённым опытом.
В крупных проектах задействовано множество таблиц, которых может быть более сотни. При этом обойтись без них невозможно, если человек имеет дело с важным и сложным проектом.
Перед составлением таблицы следует составить диаграмму или схему, в которой содержится информация о видах хранимой информации, а также о типе данных, который лучше всего подойдёт для таких целей.
NoSQL как альтернатива традиционным БД
Мир меняется. В ходе цифровой трансформации перед бизнесом встают новые задачи. Компании решают их с помощью новых баз данных. Во-первых, чтобы не перегружать имеющиеся, во-вторых, не для всех современных задач подходят классические реляционные СУБД.
И вот, в начале 2000-х появились нереляционные базы. Помимо решения новых задач, их разработчики сделали упор на исправление главных недостатков реляционных баз — проблем с гибкостью, низкой производительностью и масштабируемостью.
В NoSQL нет таких понятий, как строки, столбцы, таблицы и их соединения. Данные в нереляционных базах хранятся как объекты с произвольными атрибутами: это могут быть пары «ключ-значение», документы в формате JSON, графы и так далее.
Для чего нужны
Вот основные задачи БД на примере гардеробной:
- Сохранить наши данные по запросу — чтобы вы могли открыть дверь, повесить куртку, закрыть дверь и больше не думать ни о куртке, ни о гардеробной.
- Изменить наши данные по запросу — чтобы можно было легко извлечь из гардеробной все дырявые носки и положить на их место целые.
- Найти эти данные по запросу — чтобы быстро найти приличный пиджак или парный носок.
- Не дать прочитать эти данные тем, кому не следует, а кому надо — дать. Например, младший брат может смотреть на ваши кроссовки, но не может их брать. А девушка (или парень) может положить свои вещи, но только на определённую полку.
- Поддерживать порядок и не дать захламиться — если вам было лень и вы просто кинули толстовку куда попало, чтобы гардеробная либо сама нашла, куда эту толстовку правильно положить, либо сказала: «Э БРАТ ЗАЧЕМ ЗАХЛАМЛЯЕШЬ ПОЛОЖИ НОРМАЛЬНО ДАВАЙ»
- Масштабироваться — чтобы вы могли просто вешать в гардеробную вещи и не думать об объёме полок.
- Не потерять данные — если квартира будет гореть, приличная гардеробная не должна даже нагреться. Или, если она всё-таки горит, чтобы где-то в защищённом подземном гараже была точная копия этой гардеробной со всеми актуальными вещами.
Денормализация
Денормализация — это умышленное изменение структуры базы, нарушающее правила нормальных форм. Обычно это делается с целью улучшения производительности базы данных.
Теоретически, надо всегда стремиться к полностью нормализованной базе, однако на практике полная нормализация базы почти всегда означает падение производительности. Чрезмерная нормализация базы данных может привести к тому, что при каждом извлечении данных придется обращаться к нескольким таблицам. Обычно в запросе должны участвовать четыре таблицы или менее.
Стандартными приемами денормализации являются: объединение нескольких таблиц в одну, сохранение одинаковых атрибутов в нескольких таблицах, а также хранение в таблице сводных или вычисляемых данных.
5
11
Голоса
Рейтинг статьи
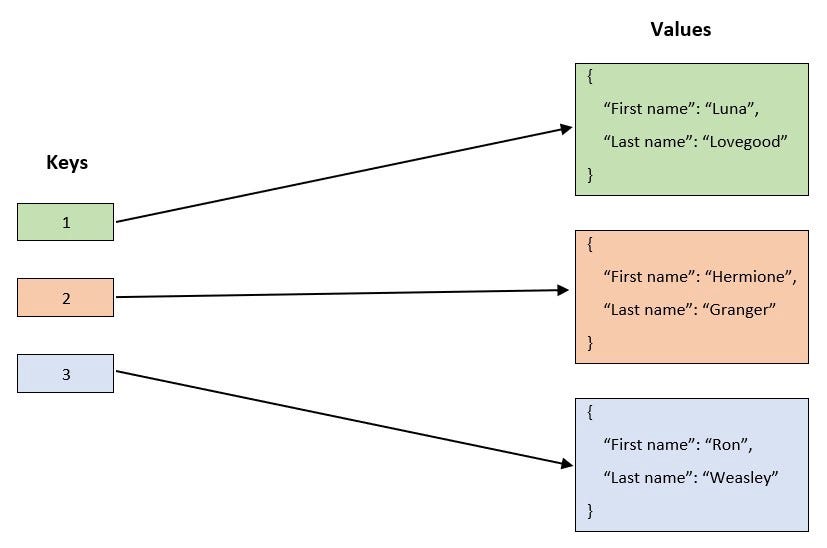
Ключ-значение
В этих БД запросы только на основе ключа — вы запрашиваете ключ и получаете его значение.
Такие БД не поддерживают запросы между различными значениями записей, вроде такого: выбрать все записи, где город — Нью-Йорк.Полезное свойство этих БД — поле времени жизни (Time-to-Live, TTL), в котором можно задать отдельно для каждой записи и состояния, когда их нужно удалить из БД.
Достоинства
Это очень быстрые БД. Во-первых, потому что используют уникальные ключи, во-вторых, потому что большинство БД типа ключ-значение хранят данные в оперативной памяти, что обеспечивает быстрый доступ к данным.
Недостатки
Необходимо определять уникальные ключи, хорошие идентификаторы, основанные на заранее известных вам данных. Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Использование
В основном используются для кэширования, потому что быстрые и не требуют сложных запросов. Поле времени жизни для кэширования также очень полезно. Такие БД могут использоваться для любых данных, которые требуют быстрых запросов и соответствуют формату ключ-значение. Примеры таких баз:
- Redis
- Memcached
Представления о преимуществах и недостатках
Аппаратная составляющая вышла на уровень гарантированной надежности, скорости и эффективности. Дело стало за малым: программная составляющая должна обеспечить свой уровень компетенции.
Одни авторы относят к преимуществам:
- контроль, избыточность, непротиворечивость данных;
- совместное использование, обеспечение их целостности;
- безопасность, стандарты, эффективность;
- компромисс при противоречивых требованиях;
- доступность, производительность работы;
- простота сопровождения, параллельная работа;
- службы резервного копирования и восстановления.
Другие смотрят на преимущества иначе:
- эффективное использование памяти и отличные показатели временных затрат на выполнение операций;
- эффективное манипулирование данными;
- одни и те же модели можно использовать для решения многих задач;
- простота моделирования и физическая реализация;
- высокая эффективность обработки.
Недостатки определяют обычно так:
- сложность, размер, стоимость;
- затраты на аппаратное обеспечение (финансы);
- затраты на преобразование (вычислительные и временные);
- серьезные последствия при выходе системы из строя;
- в контексте сетевых БД: сложность физической реализации, жесткость связи между элементами данных, ограничения на удобство манипуляции данными;
- иерархические БД: громоздкость, сложность физической реализации для больших древовидных структур;
- реляционные БД: отсутствие стандартных средств идентификации каждой записи.
Фактически области применения обуславливают различные объекты базы данных, что формирует отличия в критериях оценки преимуществ и недостатков. То что не имеет значения в одной области применения, крайне актуально в другой. Одна и та же база данных может стать причиной успеха или испортить все дело.
Сетевая модель базы данных
Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
PostgreSQL

PostgreSQL является еще одним выдающимся решением с открытым исходным кодом, работающим во всех основных операционных системах, включая Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64) и Windows. PostgreSQL полностью отвечает принципам ACID (атомарность, согласованность, изолированность, устойчивость).
Достоинства
- Возможность создания пользовательских типов данных и методов запросов;
- Среда разработки баз данных выполняет хранимые процедуры более чем на десятке языков программирования: Java, Perl, Python, Ruby, Tcl, C/C ++ и собственный PL/pgSQL;
- GiST (система обобщенного поиска): объединяет различные алгоритмы сортировки и поиска: B-дерево, B+-дерево, R-дерево, деревья частичных сумм и ранжированные B+ -деревья;
- Возможность создания для большего параллелизма без изменения кода Postgres, например, CitusDB.
Недостатки
- Система MVCC требует регулярной «чистки»: проблемы в средах с высокой скоростью транзакций;
- Разработка осуществляется обширным сообществом: слишком много усилий для улучшений.
Другие модели баз данных (ООСУБД)
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Пожалуйста, оставляйте ваши отзывы по текущей теме статьи. За комментарии, отклики, дизлайки, лайки, подписки низкий вам поклон!
Пожалуйста, оставьте ваши комментарии по текущей теме материала. Мы очень благодарим вас за ваши комментарии, лайки, отклики, подписки, дизлайки!
МКМихаил Кузнецовавтор-переводчик статьи «Types of Database Models | Database Management System»
MEMORY (HEAP)
Тип таблиц MEMORY хранится в оперативной памяти, поэтому все запросы к такой таблице выполняются очень быстро. Недостатком является полная потеря данных в случае сбоя работы сервера, поэтому в таблице данного типа хранят только временную информацию, которую можно легко восстановить заново.
При создании таблицы типа MEMORY она ассоциируется с одним-единственным файлом, имеющим расширение frm, в котором определяется структура таблицы.
При остановке или перезапуске сервера данный файл остается в текущей азе данных, но содержимое таблицы, которое хранится в оперативной памяти, теряется.
Ограничения MEMORY таблиц:
- Индексы используются только в операциях сравнения совместимо с операторами = и <=>, с другими операторами, такими как > или < индексирование столбцов не имеет смысла
- Возможно использование только неуникальных индексов.
- Можно использовать записи фиксированной длины, поэтому в них не допустимы столбцы типов TEXT и BLOD.
- В версиях, предшествующих MySQL 4.0.2, не поддерживается индексирование столбцов, содержащих NULL-значения.
Типы баз данных
Практически общепринято определять три направления, типа и существенных отличия.
Это:
- Иерархическая база данных.
- Сетевая (распределенная) база данных.
- Реляционная база данных.
Практически все ученые и специалисты сходятся в одном: реляционные отношения — основа. Все типы баз данных — это совокупность отношений между данными.
Достаточно давно в иерархических базах в деревьях отношений была замечена динамика: что поначалу было обозначено вершиной — стало основанием, а иная ветка обрела статус вершины.
Практика применения сетевых баз данных обусловила реальную потребность не только расписать одну базу данных по многим серверам, кластерам и локальным машинам, но и выполнить обратную проекцию: на множестве компьютеров разные картины (модели) от одной базы данных на одном сервере.
Область применения также определяет, какие типы баз данных допустимы в информационном пространстве задачи. Вне всякого сомнения, в большинстве случаев будет и иерархическая, и распределенная составляющие
Как именовать конкретные реляционные отношения — не суть важно
Первичные ключи
Строки в реляционной базе данных неупорядоченные. Для выбора в таблице конкретной строки создается один или несколько столбцов, значения которых во всех строках уникальны. Такой столбец называется первичным ключом.Первичный ключ (primary key) – является уникальным значением в столбце. Никакие из двух записей таблицы не могут иметь одинаковых значений первичного ключа.
По способу задания первичных ключей различают логические (естественные) ключи и суррогатные (искусственные).Логический ключ – представляет собой значение, определяющее запись естественным образом.Суррогатный ключ – представляет собой дополнительное поле в базе данных, предназначенное для обеспечения записей первичным ключом.
Использование среды SQL Server Management Studio
Создание базы данных
-
В обозревателе объектов подключитесь к экземпляру компонента Компонент SQL Server Database Engine и разверните его.
-
Щелкните правой кнопкой мыши узел Базы данных и выберите команду Создать базу данных.
-
В поле Новая база данных введите имя базы данных.
-
Чтобы создать базу данных, приняв все значения по умолчанию, нажмите кнопку ОК; в противном случае продолжайте выполнять указанные ниже дополнительные действия.
-
Чтобы изменить имя владельца, нажмите ( … ) и выберите другого владельца.
Примечание
Параметр Использовать полнотекстовое индексирование всегда установлен и недоступен (т. к. начиная с SQL Server 2008все пользовательские базы данных поддерживают полнотекстовый поиск).
-
Чтобы изменить значения первичных данных по умолчанию и файлы журнала транзакций, выберите соответствующую ячейку в сетке Файлы базы данных и введите новое значение. Дополнительные сведения см. в статье AДобавление файлов данных или журналов в базу данных.
-
Чтобы изменить параметры сортировки базы данных, выберите страницу Параметры и выберите из списка желаемые параметры сортировки.
-
Чтобы изменить модель восстановления, выберите страницу Параметры и модель восстановления из списка.
-
Чтобы изменить параметры базы данных, выберите страницу Параметры и измените параметры базы данных. Описание каждого параметра см. в статье Параметры ALTER DATABASE SET (Transact-SQL).
-
Чтобы добавить новую файловую группу, перейдите на страницу Файловые группы. Нажмите кнопку Добавить и введите значения для файловой группы.
-
Чтобы добавить расширенное свойство в базу данных, выберите страницу Расширенные свойства .
-
В столбце Имя введите имя расширенного свойства.
-
В столбце Значение введите текст расширенного свойства. Например, введите одно или несколько предложений, которые описывают базу данных.
-
-
Чтобы создать базу данных, нажмите кнопку ОК.
Бинарные связи
Бинарные связи – это связи, в которые вступают ровно две сущности. Важнейшее свойство связи – кардинальное число.
Типы бинарных связей:
- Связь типа «один-к-одному» означает, что один экземпляр первой сущности связан не более чем с одним экземпляром второй сущности и, наоборот, один экземпляр второй сущности связан не более чем с одним экземпляром первой сущности.
- Связь типа «один-ко-многим» означает, что один экземпляр первой сущности связан с несколькими экземплярами второй сущности, но при этом один экземпляр второй сущности связан не более чем с один экземпляром первой сущности.
- Связь типа «много-ко-многим» означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Эта связь должна быть заменена двумя связями типа один-ко-многим путем создания промежуточной сущности.
СУБД
Система управления базами данных — это термин, который не нужно расшифровывать. Она представляет собой встраивыемый модуль или полноценную программу, которая способна работать с данными и вносить изменения в базы.
Существует две модели СУБД — реляционная и безсхемная. О том, что такое реляционные базы данных, уже рассказано выше. Безсхемные СУБД основанные на принципах неструктурированного подхода избавляют программиста от проблем реляционной модели, в число которых входит низкая производительность и трудное масштабирование данных в горизонтальном формате.
Неструктурированные базы данных (NoSQL) создают структуру по ходу и убирают необходимость в создании жёстко определённых связей между данными. Здесь можно экспериментировать с разными способами доступа к тем или иным видам данных.
К реляционным базам данных относятся:
- SQLite;
- MySQL;
- PostgreSQL.
Из них наиболее распространённой является база данных MySQL, но остальные тоже имеют популярность и с ними можно столкнуться.
Принцип работы таких систем заключается в слежении за строгой структурой данных, которая представлена в виде комплекса таблиц. В свою очередь внутри таблицы есть ячейки и поля, которыми также управляет MySQL.
По принципу NoSQL работает база данных MongoDB. Они хранят все данные как единое целое в одной базе. При этом данные могут быть и одиночным объектом, но в то же время любой запрос не останется без ответа.
Каждая NoSQL имеет собственную систему запросов, что требует дополнительного изучения данной системы.
Добавление индексов и представлений
Индекс — это отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет быстрее находить записи. Вместо повторной сортировки для каждого запроса система может обращаться к записям в порядке, указанном индексом.
Хотя индексы ускоряют извлечение данных, они могут замедлять добавление, обновление и удаление данных, поскольку индекс нужно перестраивать всякий раз, когда изменяется запись.
Представление — это сохраненный запрос данных. Представления могут включать в себя данные из нескольких таблиц или отображать часть таблицы.
Что такое база данных в SQL
SQL-запросы обращаются к данным в виде таблиц, то есть к реляционным базам данных. Упрощенный вариант такой базы — это таблицы Excel, в которых информация также упорядочена в столбцы и строки.
Основные понятия реляционной модели:
1. Отношение — это сама таблица, она двумерная и состоит из столбцов и строк.
2. Атрибут — столбец в таблице, который содержит один конкретный параметр: название, тип, дату, стоимость или другую характеристику.
3. Домен — это допустимые значения для каждого атрибута. Например, в столбце «Имя» или «Название» значения должны представлять собой набор буквенных символов, но они не могут начинаться с «ь» или «ъ» и не могут быть записаны числами.
4. Кортеж (строка или запись) — это табличная строка с порядковым номером, в которой содержится информация об одном конкретном объекте.
5. Значение — элемент таблицы, который находится на пересечении столбцов и строк.
6. Ключ — это самый важный столбец в таблице, за счет этих значений и происходит взаимодействие в реляционной базе данных, он связывает таблицы между собой.
Ключи бывают нескольких видов:
- Первичный ключ — идентификатор, такой как индекс или артикул.
- Потенциальный ключ — другое уникальное значение, которое может служить идентификатором.
- Внешний ключ — столбец-ссылка, используется для объединения двух таблиц, каждое значение внешнего ключа обязательно соответствует первичному ключу в другой таблице.
Например, для решения задачи — выбрать все пиццерии, которые смогут доставить пиццу с ананасами после 23:00, — кроме основной таблицы с графиками работы понадобятся также таблицы с ассортиментом каждого заведения, а также таблицы с составом каждой пиццы (чтобы понять, есть ли в ней ананасы). Все эти таблицы будут связаны между собой с помощью ключей.
Список пиццерий в городе
Ассортимент одной из пиццерий с ключом id — 1
Пример: слежение за почтовыми отправлениями
Реализация — это сетевая база данных. Но не просто база или система, а разные страны и компании, которые предоставляют услугу, накапливают и обрабатывают информацию.
Это иерархическая база данных на уровне отдельно взятой компании, причем в каждой реализации будет подобная иерархия отношений. Внутри страны есть своя сетевая инфраструктура.
В каждом конкретном применении, когда посетитель веб-ресурса ищет почтовое отправление, срабатывает вся сетевая база данных, которая не была спроектирована как единое целое, но образовалась «сама по себе» вследствие области применения.
Фактор множественности реализаций и вполне конкретный запрос с ответом на него. Подобие по составляющим элементам и функциональности, а также существуют только конкретные способы предоставления почтового отправления для отправки. Есть идентичные по странам способы доставки и пересечения таможни. Результатом становится структура базы данных на местах. Это обуславливает доступность и возможность реализации «автоматического» механизма обмена данными. Но линии связи не всегда работают корректно. Сервера могут становиться и на техобслуживание.
Слово, которое вовсе не имеет значения
Главная проблема в области информации — стремительно растущая динамика, к которой пользователь не только привык, он сам ее формирует и заинтересован в адекватности используемых им инструментов.
Базы данных — не самый мобильный и динамичный инструмент. Хочет того разработчик или нет, но он всегда в плену технологий. Он не может создать базу данных, которая не поддерживается существующими СУБД, а создавать собственный вариант в 99 % случаев нет возможности и реальной необходимости.
Между тем, есть и отчасти реализуется иной подход к созданию современных информационных систем. Абстракция, которую принесло с собой объектно-ориентированное программирование и облачные технологии, позволяет определить слово, которое поначалу вовсе не имеет значения, но приобретает его с течением времени.
Каждый занимается своим делом. Базы данных работают в штатном режиме, появляются новые, модернизируются старые. Веб-ресурсы берут на себя функции систем управления базами данных на пользовательском уровне. Поисковые системы ассоциируют ключевые слова и запросы с пространством доступной информации, собранной по их уникальным критериям.
В этих двух примерах и веб-ресурсы — окошки в базы данных и поисковики, в собранную по критериям информацию, представляют собой реально работающую идею динамического использования информации.
Как начать работу с SQL
Для начала работы с SQL достаточно разбираться в основах Excel, чтобы понимать принцип работы запросов, а также иметь базовый уровень английского на уровне A1-A2. Эти навыки необходимы, чтобы понимать синтаксис SQL:
- SELECT — выбери данные
- FROM — вот отсюда
- JOIN — добавь еще эти таблицы
- WHERE — при таком условии
- GROUP BY — сгруппируй данные по этому признаку
- ORDER BY — отсортируй данные по этому признаку
- LIMIT — нужно такое количество результатов
- ; — конец предложения
Системы для работы с SQL имеют схожую структуру: есть редактор запросов, результат запросов и список таблиц, которые используются для обработки.
Самостоятельно начать изучение SQL можно с просмотра уроков на YouTube и чтения тематических статей в профильных медиа. Для более системного усвоения информации и экономии времени, потраченного на обучение, лучше записаться на курсы к опытным преподавателям, где вы сразу попадете в профессиональное сообщество и будете получать поддержку менторов.
А покажите сами запросы
А пожалуйста.
Создадим базу данных THECODE_MEDIA:
Скажем, что будем дальше работать именно с этой базой:
Создадим таблицу с названиями статей, авторами и количеством прочтений за месяц:
Загрузим в таблицу уже готовые данные из файла:
А теперь выведем их на экран:
Команд в SQL настолько много, что нам понадобится отдельная статья для практики. Сделаем для этого отдельный проект, на котором покажем, как MySQL работает с запросами и таблицами.
Работа с MySQL через запросы в терминале
Коротко главное
- MySQL — система управления реляционными базами данных. Реляционными — то есть такими, между которыми есть однозначные прописанные связи. Можно представить, что это система управления табличными базами данных.
- Таблицы могут быть связаны между собой, чтобы можно было проще найти нужную информацию.
- Для работы с реляционными БД используют специальный язык — SQL.
- Каждая команда в SQL — это запрос к базе, чтобы она что-то нашла, изменила, добавила или удалила у себя.
- MySQL используют уже 25 лет, поэтому это проверенная и надёжная база данных. Кто любит MySQL, тому легко ориентироваться в технологиях современного веба.
Что дальше
На очереди — нереляционные базы и NoSQL. Там вообще всё не так, как здесь, поэтому разбирать будем отдельно.
Текст и иллюстрации
Миша Полянин
Редактор
Максим Ильяхов
Корректор
Ира Михеева
Иллюстратор
Даня Берковский
Вёрстка
Маша Дронова






