Алгоритмы сортировки
Содержание:
- Не спеша, эффективно и правильно – путь разработки. Часть 2. Теория
- Как подготовиться и сдать экзамен ITIL 4 Foundation
- Анализ [ править ]
- Пример:
- Сортировка пузырьком Java
- Выдержки из книги Чистый код
- Функция qsort из библиотеки stdlib[править]
- Пузырьковая сортировка и её улучшения
- Варианты алгоритма
- Сортировка пузырьком
- Используйте [ редактировать ]
- Сложность алгоритмов
Не спеша, эффективно и правильно – путь разработки. Часть 2. Теория
Черновой вариант книги Никиты Зайцева, a.k.a.WildHare. Разработкой на платформе 1С автор занимается с 1996-го года, специализация — большие и по-хорошему страшные системы. Квалификация “Эксперт”, несколько успешных проектов класса “сверхтяжелая”. Успешные проекты ЦКТП. Четыре года работал в самой “1С”, из них два с половиной архитектором и ведущим разработчиком облачной Технологии 1cFresh. Ну — и так далее. Не хвастовства ради, а понимания для. Текст написан не фантазером-теоретиком, а экспертом, у которого за плечами почти двадцать три года инженерной практики на больших проектах.
Как подготовиться и сдать экзамен ITIL 4 Foundation
ITIL — библиотека, описывающая лучшие из применяемых на практике способов организации работы подразделений или компаний, занимающихся предоставлением услуг в области информационных технологий.
В начале этого года AXELOS выпустили 4 обновление библиотеки ITIL. Мне, как руководителю службы поддержки, стало интересно, что же там конкретно изменилось по сравнению с версией 3 и как эти изменения можно применить на практике. Мой интерес привёл меня к тому, что я решил закрепить свои знания и навыки по управлению ИТ подтверждающим сертификатом.
Это статья о том, как успешно подготовиться к сдаче экзамена ITIL 4 Foundation. В русскоязычном интернете мало информации на эту тему, поэтому делюсь с сообществом своим личным опытом. Эта статья для тех, кто планирует получить сертификат и не знает, с чего начать.
Анализ [ править ]
Пример пузырьковой сортировки. Начиная с начала списка, сравните каждую соседнюю пару, поменяйте их местами, если они не в правильном порядке (последняя меньше первой). После каждой итерации необходимо сравнивать на один элемент меньше (последний), пока не останется больше элементов для сравнения.
Производительность
Пузырьковая сортировка имеет наихудший случай и среднюю сложность О ( n 2 ), где n — количество сортируемых элементов. Большинство практических алгоритмов сортировки имеют существенно лучшую сложность в худшем случае или в среднем, часто O ( n log n ). Даже другое О ( п 2 ) алгоритмы сортировки, такие как вставки рода , как правило , не работать быстрее , чем пузырьковой сортировки, а не более сложным. Следовательно, пузырьковая сортировка не является практическим алгоритмом сортировки.
Единственное существенное преимущество пузырьковой сортировки перед большинством других алгоритмов, даже быстрой сортировкой , но не сортировкой вставкой , заключается в том, что в алгоритм встроена способность определять, что список сортируется эффективно. Когда список уже отсортирован (в лучшем случае), сложность пузырьковой сортировки составляет всего O ( n ). Напротив, большинство других алгоритмов, даже с лучшей средней сложностью , выполняют весь процесс сортировки на множестве и, следовательно, являются более сложными. Однако сортировка вставкой не только разделяет это преимущество, но также лучше работает со списком, который существенно отсортирован (с небольшим количеством инверсий).). Кроме того, если такое поведение желательно, его можно тривиально добавить к любому другому алгоритму, проверив список перед запуском алгоритма.
В случае больших коллекций следует избегать пузырьковой сортировки. Это не будет эффективно в случае коллекции с обратным порядком.
Кролики и черепахи
Расстояние и направление, в котором элементы должны перемещаться во время сортировки, определяют производительность пузырьковой сортировки, поскольку элементы перемещаются в разных направлениях с разной скоростью. Элемент, который должен двигаться к концу списка, может перемещаться быстро, потому что он может принимать участие в последовательных заменах. Например, самый большой элемент в списке будет выигрывать при каждом обмене, поэтому он перемещается в свою отсортированную позицию на первом проходе, даже если он начинается с начала. С другой стороны, элемент, который должен двигаться к началу списка, не может двигаться быстрее, чем один шаг за проход, поэтому элементы перемещаются к началу очень медленно. Если наименьший элемент находится в конце списка, он займет n −1проходит, чтобы переместить его в начало. Это привело к тому, что эти типы элементов были названы кроликами и черепахами соответственно в честь персонажей басни Эзопа о Черепахе и Зайце .
Были предприняты различные попытки уничтожить черепах, чтобы повысить скорость сортировки пузырей. Сортировка коктейлей — это двунаправленная сортировка пузырьков, которая идет от начала до конца, а затем меняет свое направление, идя от конца к началу. Он может довольно хорошо перемещать черепах, но сохраняет сложность наихудшего случая O (n 2 ) . Комбинированная сортировка сравнивает элементы, разделенные большими промежутками, и может очень быстро перемещать черепах, прежде чем переходить к все меньшим и меньшим промежуткам для сглаживания списка. Его средняя скорость сопоставима с более быстрыми алгоритмами вроде быстрой сортировки .
Пошаговый пример
Возьмите массив чисел «5 1 4 2 8» и отсортируйте его от наименьшего числа к наибольшему, используя пузырьковую сортировку. На каждом этапе сравниваются элементы, выделенные жирным шрифтом . Потребуется три прохода;
- Первый проход
- ( 5 1 4 2 8) → ( 1 5 4 2 8). Здесь алгоритм сравнивает первые два элемента и меняет местами, поскольку 5> 1.
- (1 5 4 2 8) → (1 4 5 2 8), поменять местами, поскольку 5> 4
- (1 4 5 2 8) → (1 4 2 5 8), поменять местами, поскольку 5> 2
- (1 4 2 5 8 ) → (1 4 2 5 8 ). Теперь, поскольку эти элементы уже упорядочены (8> 5), алгоритм не меняет их местами.
- Второй проход
- ( 1 4 2 5 8) → ( 1 4 2 5 8)
- (1 4 2 5 8) → (1 2 4 5 8), поменять местами, поскольку 4> 2
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8 ) → (1 2 4 5 8 )
Теперь массив уже отсортирован, но алгоритм не знает, завершился ли он. Алгоритм нужен один весь проход без какой — либо свопа знать сортируется.
- Третий проход
- ( 1 2 4 5 8) → ( 1 2 4 5 8)
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8 ) → (1 2 4 5 8 )
Пример:
Пусть исходный массив будет .
Первая итерация:
сравните элементы в индексах 1 и 2: 5, 4. Они не отсортированы. Поменяйте их местами. Array = .
Сравните элементы в индексе 2 и 3: 5, 9. Они отсортированы. Не меняйте местами. Array = .
Сравните элементы в индексе 3 и 4: 9, 3. Они не отсортированы. Поменяйте их местами. Array = .
Сравните элементы в индексе 4 и 5: 9, 7. Они не отсортированы. Поменяйте их местами. Array = .
Сравните элементы в индексе 5 и 6: 9, 6. Они не отсортированы. Поменяйте их местами. Array =
Массив после первой итерации равен .
В таблице ниже описан полный процесс сортировки, включая другие итерации. Для краткости показаны только шаги, на которых происходит замена.
Первая итерация:
Вторая итерация:
Третья итерация:
Исходный код: пузырьковая сортировка
def bubble_sort(arr, n): for i in range(0, n): for j in range(0, n-1): # Если пара не находится в отсортированном порядке if arr > arr: # Поменяйте местами пары, чтобы сделать их в отсортированном порядке arr, arr = arr, arr return arr if __name__ == "__main__": arr = n = len(arr) arr = bubble_sort(arr, n) print (arr)
Пояснение: Алгоритм состоит из двух циклов. Первый цикл повторяется по массиву n раз, а второй цикл n-1 раз. На каждой итерации первого цикла второй цикл сравнивает все пары соседних элементов. Если они не отсортированы, соседние элементы меняются местами, чтобы упорядочить их. Максимальное количество сравнений, необходимых для присвоения элементу его правой позиции в отсортированном порядке, равно n-1, потому что есть n-1 других элементов. Так как имеется n элементов, и каждый элемент требует максимум n-1 сравнений; массив сортируется за время O (n ^ 2). Следовательно, временная сложность наихудшего случая равна O (n ^ 2). Лучшая временная сложность в этой версии пузырьковой сортировки также составляет O (n ^ 2), потому что алгоритм не знает, что он полностью отсортирован. Следовательно, даже если он отсортирован.
Сортировка пузырьком Java
// Java программа реализации пузырьковой сортировки
class BubbleSort
{
void bubbleSort(int arr[])
{
int n = arr.length;
for (int i = 0; i < n-1; i++)
for (int j = 0; j < n-i-1; j++)
if (arr > arr)
{
// меняем местами temp и arr
int temp = arr;
arr = arr;
arr = temp;
}
}
/* Вывод массива на экран */
void printArray(int arr[])
{
int n = arr.length;
for (int i=0; i<n; ++i)
System.out.print(arr + " ");
System.out.println();
}
// Метод, тестирующий функции, приведенные выше
public static void main(String args[])
{
BubbleSort ob = new BubbleSort();
int arr[] = {64, 34, 25, 12, 22, 11, 90};
ob.bubbleSort(arr);
System.out.println("Sorted array");
ob.printArray(arr);
}
}
Выдержки из книги Чистый код
Недавно я прочитал книгу «Чистый код» Роберта Мартина (Robert Cecil Martin). В ней описываются принципы организации и форматирование исходного кода программы так, чтобы в дальнейшем было легко поддерживать такой код.
Эта книга является библией для многих программистов, но вот в среде программистов 1С, к сожалению, не очень распространено чтение подобной фундаментальной литературы.
Книга более 400 страниц и так много порой лениво читать, да и времени всегда не хватает. По этому я решил выделить в виде цитирования по разделам самые важные моменты. А также снабдил текст своими примерами кода.
Функция qsort из библиотеки stdlib[править]
Два оператора for, в которых происходит сортировка, можно заменить на одну строку:
qsort(a,n,sizeof(int),cmp);
Это функция, описанная в стандартной библиотеке ANSI C и объявлена в заголовочном файле stdlib.h.
Поэтому в начале программы нужно добавить
#include<stdlib.h>
Функцией можно упорядочивать объекты любой природы. По сути, она предназначена упорядочивать множества блоков байтов равной длины.
Второй аргумент функции — это число таких блоков, третий аргумент — длина каждого блока.
Первый аргумент — это адрес, где находится начало первого блока (предполагается, что блоки в памяти расположены друг за другом подряд).
Четвёртый аргумент функции qsort — это имя функции, которая умеет сравнивать
два элемента массива. В нашем случае это
intcmp(constvoid*a,constvoid*b){
return*(int*)a-*(int*)b;
}
В силу указанной универсальности функции сортировки, функция сравнения получает в качества аргумента адреса двух блоков, которые нужно сравнить и возвращает 1, 0 или -1:
- положительное значение, если a > b
- 0, если a == b
- отрицательное значение, если a < b
Поскольку у нас блоки байт — это целые числа (в 32-битной архитектуре это четырёхбайтовые блоки), то
необходимо привести данные указатели типа (const void*) к типу (int *) и осуществляется это с помощью дописывания
перед указателем выражения «(const int*)». Затем нужно получить значение переменной типа int, которая лежит по этому адресу.
Это делается с помощью дописывания спереди звездочки.
Таким образом, мы получили следующую программу
#include<stdio.h>
#include<stdlib.h>
#define N 1000
intcmp(constvoid*a,constvoid*b){
return*(int*)a-*(int*)b;
}
intmain(){
intn,i,j;
intaN];
scanf("%d",&n);
for(i=;i<n;i++){// ЧИТАЕМ ВХОД
scanf("%d",&ai]);
}
qsort(a,n,sizeof(int),cmp);// СОРТИРУЕМ
for(i=;i<n;i++){// ВЫВОДИМ РЕЗУЛЬТАТ
printf("%d ",ai]);
}
return;
}
Пузырьковая сортировка и её улучшения
Сортировка пузырьком

Сортировка пузырьком — один из самых известных алгоритмов сортировки. Здесь нужно последовательно сравнивать значения соседних элементов и менять числа местами, если предыдущее оказывается больше последующего. Таким образом элементы с большими значениями оказываются в конце списка, а с меньшими остаются в начале.
Этот алгоритм считается учебным и почти не применяется на практике из-за низкой эффективности: он медленно работает на тестах, в которых маленькие элементы (их называют «черепахами») стоят в конце массива. Однако на нём основаны многие другие методы, например, шейкерная сортировка и сортировка расчёской.
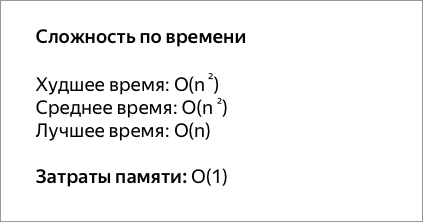
void BubbleSort(vector<int>& values) {
for (size_t idx_i = 0; idx_i + 1 < values.size(); ++idx_i) {
for (size_t idx_j = 0; idx_j + 1 < values.size() - idx_i; ++idx_j) {
if (values < values) {
swap(values, values);
}
}
}
}
Сортировка перемешиванием (шейкерная сортировка)
Шейкерная сортировка отличается от пузырьковой тем, что она двунаправленная: алгоритм перемещается не строго слева направо, а сначала слева направо, затем справа налево.
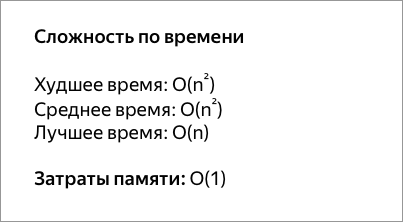
void ShakerSort(vector<int>& values) {
if (values.empty()) {
return;
}
int left = 0;
int right = values.size() - 1;
while (left <= right) {
for (int i = right; i > left; --i) {
if (values > values) {
swap(values, values);
}
}
++left;
for (int i = left; i < right; ++i) {
if (values > values) {
swap(values, values);
}
}
--right;
}
}
Сортировка расчёской
Сортировка расчёской — улучшение сортировки пузырьком. Её идея состоит в том, чтобы «устранить» элементы с небольшими значения в конце массива, которые замедляют работу алгоритма. Если при пузырьковой и шейкерной сортировках при переборе массива сравниваются соседние элементы, то при «расчёсывании» сначала берётся достаточно большое расстояние между сравниваемыми значениями, а потом оно сужается вплоть до минимального.
Первоначальный разрыв нужно выбирать не случайным образом, а с учётом специальной величины — фактора уменьшения, оптимальное значение которого равно 1,247. Сначала расстояние между элементами будет равняться размеру массива, поделённому на 1,247; на каждом последующем шаге расстояние будет снова делиться на фактор уменьшения — и так до окончания работы алгоритма.

void CombSort(vector<int>& values) {
const double factor = 1.247; // Фактор уменьшения
double step = values.size() - 1;
while (step >= 1) {
for (int i = 0; i + step < values.size(); ++i) {
if (values > values) {
swap(values, values);
}
}
step /= factor;
}
// сортировка пузырьком
for (size_t idx_i = 0; idx_i + 1 < values.size(); ++idx_i) {
for (size_t idx_j = 0; idx_j + 1 < values.size() - idx_i; ++idx_j) {
if (values < values) {
swap(values, values);
}
}
}
}
Варианты алгоритма
Сорт коктейлей
Производной пузырьковой сортировки является сортировка коктейлей или шейкерная сортировка. Этот метод сортировки основан на следующем наблюдении: при пузырьковой сортировке элементы могут быстро перемещаться в конец массива, но перемещаются в начало массива только по одной позиции за раз.
Идея сортировки коктейлей состоит в чередовании направления маршрута. Получается несколько более быстрая сортировка, с одной стороны, потому что она требует меньшего количества сравнений, с другой стороны, потому что она перечитывает самые последние данные при изменении направления (поэтому они все еще находятся в кэш-памяти ). Однако количество обменов, которые необходимо произвести, идентично (см. Выше). Таким образом, время выполнения всегда пропорционально n 2 и, следовательно, посредственно.
Три прыжка вниз
Код для этой сортировки очень похож на пузырьковую сортировку. Подобно пузырьковой сортировке, при этой сортировке первыми отображаются самые крупные элементы. Однако это не работает с соседними элементами; он сравнивает каждый элемент массива с тем, который находится на месте большего, и обменивается, когда находит новый, больший.
tri_jump_down(Tableau T)
pour i allant de taille de T - 1 à 1
pour j allant de 0 à i - 1
si T < T
échanger(T, T)
Сортировка combsort
Вариант пузырьковой сортировки, называемый гребенчатой сортировкой ( combsort ), был разработан в 1980 году Влодзимежем Добосевичем и вновь появился в апреле 1991 года в журнале Byte Magazine . Он исправляет главный недостаток пузырьковой сортировки, которой являются «черепахи», и делает алгоритм столь же эффективным, как и быстрая сортировка .
Сортировка пузырьком
Идея алгоритма очень простая. Идём по массиву чисел и проверяем порядок (следующее число должно быть больше и равно предыдущему), как только наткнулись на нарушение порядка, тут же обмениваем местами элементы, доходим до конца массива, после чего начинаем сначала.
Отсортируем массив {1, 5, 2, 7, 6, 3}
Идём по массиву, проверяем первое число и второе, они идут в порядке возрастания. Далее идёт нарушение порядка, меняем местами эти элементы
Продолжаем идти по массиву, 7 больше 5, а вот 6 меньше, так что обмениваем из местами
3 нарушает порядок, меняем местами с 7
Возвращаемся к началу массива и проделываем то же самое
void bubbleSort(int *a, size_t size) {
size_t i, j;
int tmp;
for (i = 1; i < size; i++) {
for (j = 1; j < size; j++) {
if (a > a) {
tmp = a;
a = a;
a = tmp;
}
}
}
}
Этот алгоритм всегда будет делать (n-1)2 шагов, независимо от входных данных. Даже если массив отсортирован, всё равно он будет пройден (n-1)2 раз. Более того, будут в очередной раз проверены уже отсортированные данные.
Пусть нужно отсортировать массив 1, 2, 4, 3
После того, как были поменяны местами элемента a и a нет больше необходимости проходить этот участок массива
Примем это во внимание и переделаем алгоритм
void bubbleSort2(int *a, size_t size) {
size_t i, j;
int tmp;
for (i = 1; i < size; i++) {
for (j = i; j > 0; j--) {
if (a < a) {
tmp = a;
a = a;
a = tmp;
}
}
}
}
Ещё одна реализация
void bubbleSort2b(int *a, size_t size) {
size_t i, j;
int tmp;
for (i = 1; i < size; i++) {
for (j = 1; j <= size-i; j++) {
if (a < a) {
tmp = a;
a = a;
a = tmp;
}
}
}
}
В данном случае будет уже вполовину меньше шагов, но всё равно остаётся проблема сортировки уже отсортированного массива: нужно сделать так, чтобы отсортированный массив функция просматривала один раз. Для этого введём переменную-флаг: он будет опущен (flag = 0), если массив отсортирован. Как только мы наткнёмся на нарушение порядка, то флаг будет поднят (flag = 1) и мы начнём сортировать массив как обычно.
void bubbleSort3(int *a, size_t size) {
size_t i;
int tmp;
char flag;
do {
flag = 0;
for (i = 1; i < size; i++) {
if (a < a) {
tmp = a;
a = a;
a = tmp;
flag = 1;
}
}
} while (flag);
}
В этом случае сложность также порядка n2, но в случае отсортированного массива будет всего один проход.
Теперь усовершенствуем алгоритм. Напишем функцию общего вида, чтобы она сортировала массив типа void. Так как тип переменной не известен, то нужно будет дополнительно передавать размер одного элемента массива и функцию сравнения.
int intSort(const void *a, const void *b) {
return *((int*)a) > *((int*)b);
}
void bubbleSort3g(void *a, size_t item, size_t size, int (*cmp)(const void*, const void*)) {
size_t i;
void *tmp = NULL;
char flag;
tmp = malloc(item);
do {
flag = 0;
for (i = 1; i < size; i++) {
if (cmp(((char*)a + i*item), ((char*)a + (i-1)*item))) {
memcpy(tmp, ((char*)a + i*item), item);
memcpy(((char*)a + i*item), ((char*)a + (i-1)*item), item);
memcpy(((char*)a + (i-1)*item), tmp, item);
flag = 1;
}
}
} while (flag);
free(tmp);
}
Функция выглядит некрасиво – часто вычисляется адрес текущего и предыдущего элемента. Выделим отдельные переменные для этого.
void bubbleSort3gi(void *a, size_t item, size_t size, int (*cmp)(const void*, const void*)) {
size_t i;
void *tmp = NULL;
void *prev, *cur;
char flag;
tmp = malloc(item);
do {
flag = 0;
i = 1;
prev = (char*)a;
cur = (char*)prev + item;
while (i < size) {
if (cmp(cur, prev)) {
memcpy(tmp, prev, item);
memcpy(prev, cur, item);
memcpy(cur, tmp, item);
flag = 1;
}
i++;
prev = (char*)prev + item;
cur = (char*)cur + item;
}
} while (flag);
free(tmp);
}
Теперь с помощью этих функций можно сортировать массивы любого типа, например
void main() {
int a = {1, 0, 9, 8, 7, 6, 2, 3, 4, 5};
int i;
bubbleSort3gi(a, sizeof(int), 10, intSort);
for (i = 0; i < 10; i++) {
printf("%d ", a);
}
_getch();
}
Используйте [ редактировать ]
Пузырьковая сортировка — алгоритм сортировки, который непрерывно просматривает список, меняя местами элементы, пока они не появятся в правильном порядке. Список был построен в декартовой системе координат, где каждая точка ( x , y ) указывает, что значение y хранится в индексе x . Затем список будет отсортирован пузырьковой сортировкой по значению каждого пикселя
Обратите внимание, что сначала сортируется самый большой конец, а меньшим элементам требуется больше времени, чтобы переместиться в правильное положение.
Хотя пузырьковая сортировка является одним из простейших алгоритмов сортировки для понимания и реализации, ее сложность O ( n 2 ) означает, что ее эффективность резко снижается в списках из более чем небольшого числа элементов. Даже среди простых алгоритмов сортировки O ( n 2 ) такие алгоритмы, как сортировка вставкой , обычно значительно более эффективны.
Из-за своей простоты пузырьковая сортировка часто используется для ознакомления с концепцией алгоритма или алгоритма сортировки для начинающих студентов- информатиков . Тем не менее, некоторые исследователи, такие как Оуэн Астрахан , пошли на многое, чтобы осудить пузырьковую сортировку и ее неизменную популярность в образовании по информатике, рекомендуя даже не преподавать ее.
Жаргон Файл , который лихо звонков bogosort «архетипический извращенно ужасный алгоритм», также вызывает пузырьковую сортировку «общий плохой алгоритм». Дональд Кнут в книге «Искусство компьютерного программирования» пришел к выводу, что «пузырьковая сортировка, похоже, не имеет ничего, что могло бы ее рекомендовать, кроме броского названия и того факта, что она приводит к некоторым интересным теоретическим проблемам», некоторые из которых он затем обсуждает. .
Пузырьковая сортировка асимптотически эквивалентна по времени работы сортировке вставкой в худшем случае, но эти два алгоритма сильно различаются по количеству необходимых перестановок. Экспериментальные результаты, такие как результаты Astrachan, также показали, что сортировка вставкой работает значительно лучше даже в случайных списках. По этим причинам многие современные учебники алгоритмов избегают использования алгоритма пузырьковой сортировки в пользу сортировки вставкой.
Пузырьковая сортировка также плохо взаимодействует с современным аппаратным обеспечением ЦП. Он производит как минимум вдвое больше записей, чем сортировка вставкой, вдвое больше промахов в кеш и асимптотически больше ошибочных прогнозов переходов . [ необходима цитата ] Эксперименты по сортировке строк Astrachan в Java показывают, что пузырьковая сортировка примерно в пять раз быстрее сортировки вставкой и на 70% быстрее сортировки по выбору .
В компьютерной графике пузырьковая сортировка популярна благодаря своей способности обнаруживать очень маленькие ошибки (например, перестановку всего двух элементов) в почти отсортированных массивах и исправлять их с линейной сложностью (2 n ). Например, он используется в алгоритме заполнения многоугольника, где ограничивающие линии сортируются по их координате x в определенной строке сканирования (линия, параллельная оси x ), а с увеличением y их порядок изменяется (два элемента меняются местами) только при пересечения двух линий. Пузырьковая сортировка — это стабильный алгоритм сортировки, как и сортировка вставкой.
Сложность алгоритмов
Тему сложности алгоритмов часто трудно понять многим программистам и студентам, они стараются пропускать ее. На сам деле она довольна проста. Сложность — это способ измерения того, как быстро работает программа.
Время выполнения описывает, сколько операций должен выполнить алгоритм до его завершения. Пространственная сложность — сколько места должно быть выделено для запуска. Например, если алгоритм принимает список размером n и по какой-то причине создает новый с таким же для каждого элемента в n, то требуется пространство n2 . Кроме того, иногда полезно знать устойчивость выполнения. Алгоритм стабилен, если он сохраняет исходный порядок элементов с одинаковыми значениями.
Таблица сложности алгоритмов:
| Алгоритм | Пространственная сложность | Худший случай | Средний случай | Лучший случай | Стабильный |
| Сортировка слиянием | О (n) | O (n lоg n) | O (n log n) | O (n lоg n) | Да |
| Сортировка вставками | О (1) | O (n 2 ) | O (n 2 ) | O (n) | Да |
| Сортировка пузырьком | О (1) | O (n 2 ) | O (n 2 ) | O (n) | Да |
| Быстрая | lоg n | O (n 2 ) | O (n log n) | O (n lоg n) | Обычно нет* |
| Сортировка блоками | O (1) | O (n lоg n) | O (n log n) | O (n lоg n) | Нет |
| Сортировка подсчетом | O (k+n) | O (k+n) | O (k+n) | O (k+n) | Да |
При выборе используемого алгоритма нужно взвесить эти факторы. Например, быстрая является очень шустрой, но ее может быть довольно сложно реализовать. Пузырьковая сортировка — медленный алгоритм, но его очень легко сделать. Для небольших наборов данных может быть лучше использовать вторую, поскольку она может быть реализована не так трудно, но для больших стоит использовать быструю.






