Инструкция по настройке и работе с key collector
Содержание:
- Главное меню программы
- Навигация по группам
- Настройки в зависимости от размера семантики
- Что такое Key Collector?
- Редактирование ячеек
- О возможных последствиях и ответственности в результате использования Key Collector
- Работа с пользовательскими группами
- Работа с группировками запросов
- Переименование и цветовая маркировка
- Борьба с погрешностями и операторы поиска
- Сбор частот
- Подбираем маски
- Заключение
- Вывод
Главное меню программы
Для того, чтобы попасть в меню нам нужно в верхнем правом углу выбрать “Файл”.

Добро пожаловать в Key Collector!
В появившемся меню вы можете создать новый файл или открыть уже ранее существующий проект, импортировать данные из другого проекта или файла в формате CSV.
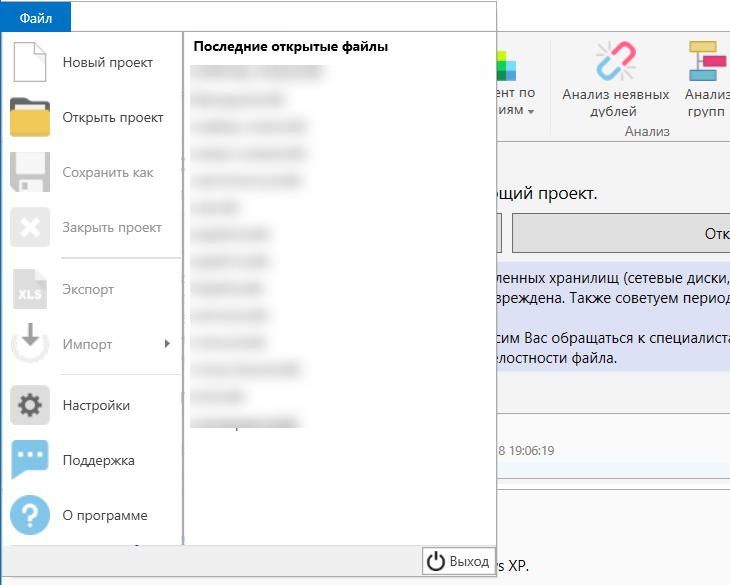
Загрузка проекта
Меню быстрого доступа
Используя меню быстрого доступа вы можете добавить наиболее часто используемые кнопки.
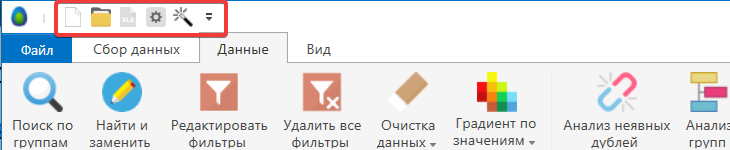
Меню быстрого доступа
Для добавления новых элементов нужно правой кнопкой мышки нажать на интересующий значок. После чего в появившемся окне выбрать пункт “Добавить в панель быстрого доступа”
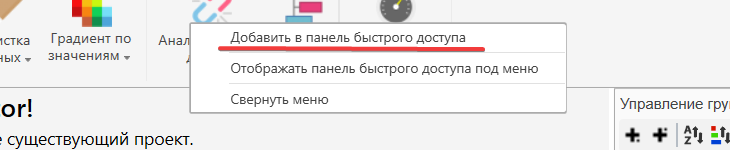
Добавить в палень быстрого доступа
Теперь данный элемент будет добавлен в меню. Если вы захотите удалить кнопку из меню быстрого доступа, тогда проделайте аналогичные действия: нажмите правой кнопкой мышки на иконку и дальше в меню выберите “Удалить с панели быстрого доступа”.
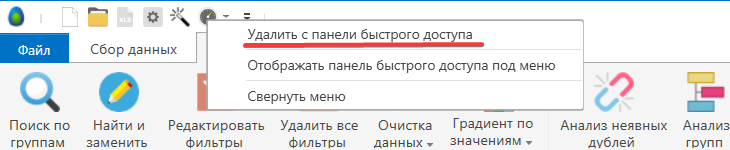
Удалить с панели быстрого доступа
Основная рабочая область
Основную рабочую область используют для отображения пользовательских групп и экрана приветствия после запуска программы. В ней вы можете ознакомиться со свежими новостям относительно программы, увидеть статистику хода выполнения работы и т.д.
Область новостей, журнала событий и статистика

Область новостей, журнала событий и статистика
Данная вкладка предназначена для:
-
Отображения журнала событий.
-
Получения последних новостей программы.
-
Просмотра статистики по текущему выполнению задач.
-
Просмотра дополнительных данных статистики: отображение списка релевантных страниц, графиков истории позиций, сезонности, поисковой выдачи и тд.
Под просмотром дополнительной статистики имеется в виду просмотр тех данных, которые не могут быть показаны в стандартных таблицах и выводятся для каждой фразы в отдельности. К дополнительной статистике принадлежит:
-
Просмотр количества акноров с помощью сервиса Solomono. Используем кнопку “Количество анкоров Solomono”.
-
Просмотр с помощью графика или в виде таблицы истории позиций. Для этого нажимаем “Позиция Yandex” и “Позиция Google”.
-
Просмотр состава поисковой выдачи по какому-либо запросу: адреса страниц, заголовки, сниппеты. Для этого используем «Кол-во вхождений в заголовок «, «Кол-во вхождений в заголовок » и «Кол-во вхождений в заголовок «.
-
Просмотр релевантных страниц — колонки «Рел. страница » и «Рел. страница «.
-
Просмотр частотности слов по месяцам для Google Adwors — колонка «Частотность (регионы) »
-
Просмотр частотности для Yandex Wordstats по неделям и месяцам. Для этого переходим в раздел «Сезонность «.
Для того, чтобы увидеть данную статистику надо выбрать нужную фразу и перейти во вкладку “Дополнительная статистика”. В этом меню будет доступна интересующая подвкладка с дополнительной статистикой.
Отображение вкладок можно настроить на свое усмотрение. Для этого надо зажать левую кнопку мышки на заголовок с вкладкой и перетащить в нужную сторону.

Отображение вкладок
Панель состояния
Панель состояния нужна для показа информации о количестве отмеченных строк и информацию об использовании автоматической капчи.

Панель состояния
Выше выделена кнопка принудительного обновления содержимого активной таблицы.
Навигация по группам
При работе со сложными структурами иногда хочется сконцентрировать внимание на каком-нибудь одном разделе проекта. Для перехода внутрь структуры вызовите контекстное меню к интересующей родительской группе и выберите пункт «Перейти в эту группу»
Для перехода внутрь структуры вызовите контекстное меню к интересующей родительской группе и выберите пункт «Перейти в эту группу».
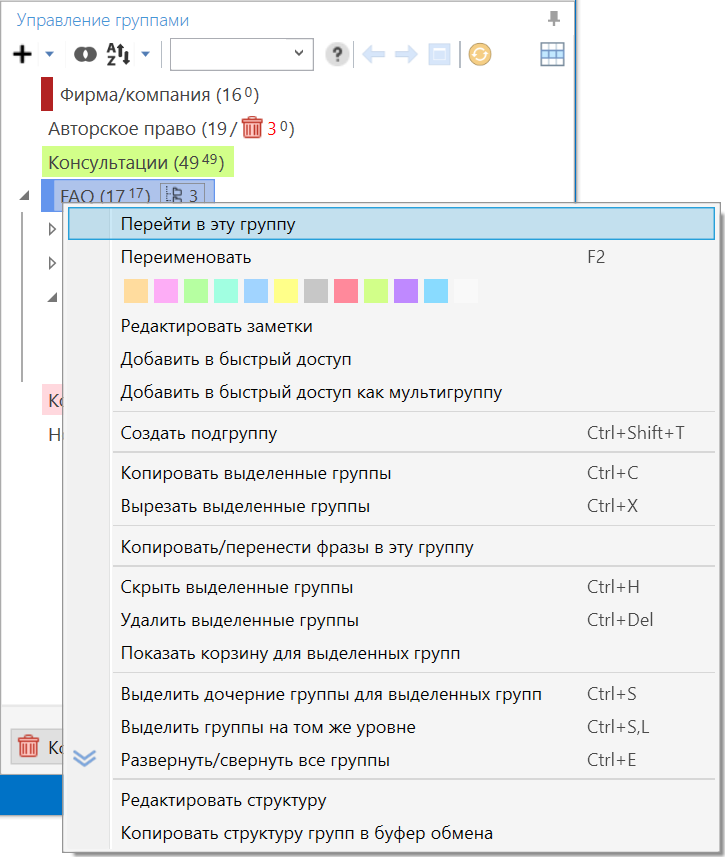
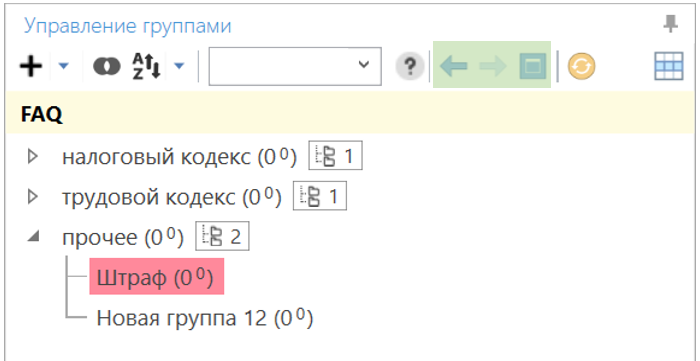
С этого момента дерево будет содержать только дочерние узлы выбранной родительской группы. При этом вы можете перейти глубже по структуре или же вернуться назад (для навигации воспользуйтесь кнопками в панели инструментов над списком групп).
Переход в группу — это навигационная операция в панели групп, которая не влияет на отображаемые фразы в таблице. Для отображения фраз какой-либо группы дополнительно потребуется выбрать нужную группу в панели.
Переключение между последними активными группами
Часто возникает необходимость попеременно просматривать содержимое то одной, то другой группы или же требуется вернуться к ранее загруженной мультигруппе с заданными условиями сортировки и фильтрации.
Для этого предусмотрена функция перехода назад и вперед в контекстном меню панели управления группами (вызывать его требуется не на заголовке группы, а на свободной области панели).

В отличие от навигационного «перехода в группу» речь идет о переключении отображаемого в таблице содержимого группы.
Настройки в зависимости от размера семантики
Настройки для небольшой семантики (от 0 до 1 000 ключей).
Дальше все настройки зависят от того какая скорость сбора семантика вам требуется, если семантика небольшая, то и времени на ее парсинг уйдет немного.
Тогда можно обойтись добавлением одного (не основного!) аккаунта Яндекса для парсинга и можно приступать.
-
Выбираем пункт меню Yandex.Direct
-
Жмем кнопку «Добавить строку»
-
Вводим логин и пароль от аккаунта Яндекса
-
Нажимаем на кнопку пуск для проверки работоспособности аккаунта
И Жмем сохранить изменения
Настройки Yandex Direct в Key Collector
Настройки для средних и больших семантик (более 1 000 ключей)Сначала теория
Для настройки парсинга средних или больших семантических ядер потребуется расширить количество потоков и соответственно количество аккаунтов Яндекс Директ для ускорения сбора ключевых фраз.
Принцип сбора заключается в том, что Key Collector используя добавленные в него аккаунты Яндекса, обращается к yandex wordstat и постранично копирует все выданные запросы по ключевой фразе (если страница полная, то запросов в левой колонке ровно 50)
далее уходит в ожидание на 25-30 секунд, для избежания бана аккаунта и после этого еще раз обращается уже к следующей странице, либо к следующей фразе. В итоге получается 100 запросов в минуту, не считая перехода на другое ключевое слово, т.е. примерно 6 000 запросов в час.
Следовательно, если требуется собрать большие семантики на 10 000 – 20 000 слов потребуется от 2 часов и более.
А если у вас сразу несколько тематик и количество ключевых фраз более 100 000? На их сбор уйдет слишком много времени.
Для увеличения скорости требуется увеличивать количество потоков, при этом скорость увеличивается ровно во столько раз сколько будет добавлено потоков.
Для этого потребуется равное количество Яндекс аккаунтов и готовых прокси серверов. Их можно приобрести на специальных площадках. В среднем, цена за один прокси + один аккаунт Яндекса — 100 рублей в месяц.
Мы используем 10 прокси и соответственно 10 аккаунтов Яндекса.
Это примерно 1 000 запросов в минуту.
Перейдем к настройке
Заходим в настройки Yandex.Wordstat и отключаем галочку напротив «Использовать основной Ip-адрес»
Здесь же выставляем количество потоков равное количеству доступных нам прокси и аккаунтов Яндекса.
Если вы приобрели 10 прокси и 8 Яндекс аккаунтов, то выставляйте 8 потоков, чтобы не повышать шансы блокировки Яндекс аккаунтов.
Настройка Yandex Wordstat в Key Collector
Для дальнейшей настройки переходим во вкладку Яндекс директ.
Жмем по кнопке добавить списком и вносим сюда все аккаунты по шаблону логин:пароль.
Настройки Яндекс Директ в Key Collector часть 1
После внесения списка аккаунтов требуется их проверить на работоспосоность:
-
Пролистываем настройки чуть ниже.
-
Нажимаем на зеленую кнопку запустить — все рабочие аккаунты отобразятся как зеленые, нерабочие красные.
-
Выставляем количество потоков
-
Снимаем галочку с использования основного ip-адреса.
Настройки Яндекс Директ в Key Collector
Переходим во вкладку «Сеть»
Вкладка Сеть настройки Key Collector
-
Здесь ставим галочку на пункте «Использовать прокси-серверы»
-
Далее нажимаем кнопку «Добавить из буфера»
Настройки Сети Key Collector
Копируем сюда прокси по шаблону адрес:порт@логин:пароль.
Настройка прокси кей коллектор
После добавления проверяем прокси также, как и с Яндекс директом, красные не рабочие, зеленые в полном порядке.
Нажимаем кнопку сохранить изменения.
Проверка прокси в кей коллектор
С настройками закончили. Данных настроек вполне хватит для сбора семантики и ее частотности. На свой страх и риск можно также протестировать настройки паузы между запросами для увеличения скорости сбора.
Что такое Key Collector?
Кей Коллектор – это платная утилита, которая повсеместно используется сеошниками и маркетологами. Суть ее состоит в почти полной автоматизации сбора семантического ядра. Приложение тесно интегрировано с Яндекс Директом, Вордстатом, гугловскими сервисами и прочими инструментами, которые поодиночке не выглядят такими практичными.
То есть Key Collector объединяет в себе несколько сервисов, интегрируя их возможности. Это позволяет людям легко и просто парсить запросы с того же Вордстата или Директа, в последствии превращая их во вполне себе обоснованное семантическое ядро.
Как я уже сказал, чтобы пользоваться программой, ее придется купить. Разработчики очень сильно заботятся о сохранении лицензии, поэтому каждая отдельная программа привязывается к одному персональному компьютеру с помощью идентификатора жесткого диска. Следовательно, вы не сможете скачать приложение, чтобы использовать его на нескольких машинах – 1 лицензия для 1 компьютера.
В интернете, конечно, есть взломанные версии, которые якобы предоставляют те же возможности, что и оригинал. Однако стоит учитывать, что через пиратское ПО очень часто распространяются вирусы
Если уж вы не хотите покупать Коллектор, то я бы рекомендовал вам обратить внимание на СловоЁб. Это бесплатное приложение от тех же разработчиков, которое представляет собой урезанный вариант Коллектора
Теперь давайте более подробно рассмотрим возможности программы. Итак, как заявляют разработчики, с помощью Key Collector мы сможем составить более точное семантическое ядро, не прибегая к помощи сторонних специалистов. Нам лишь нужно правильно настроить все параметры и познать некоторые азы.
Надо сказать, что Key Collector не работает с готовыми базами данных, которые требуют постоянные обновления. Он парсит всю информацию в реальном времени через интернет, подключаясь ко все тем же сервисам: Вордстат, Яндекс Директ, Гугл Адвордс и прочим. Такой подход гарантирует вам актуальность всех ключей, которые вы получите на выходе.
Эта программа поможет вам увидеть наиболее популярные страницы вашего сайта, определить верную стратегию продвижения, основываясь на статистических данных. В конечном итоге вы можете выгрузить всю информацию в удобный формат, например, в таблицу Excel.
Я уверен, что купить программу определенно стоит. Если понять, как работать, то это может сэкономить существенную часть финансов и времени. Да и проекты с качественной семантикой будут давать больше отдачи, что также является плюсом.
Редактирование ячеек
Вы можете изменять значения ячеек в таблице. При этом редактировать можно как сами фразы, так и данные в колонках статистики (если они не заблокированы для редактирования).
Перед редактированием фраз убедитесь, что это разрешено в «Настройках — Интерфейс — Таблица данных — Управление таблицей».
Для редактирования фразы нажмите клавишу F2 или совершите двойной клик мышкой по фразе. Ячейка перейдет в режим редактирования.
В силу ограничения уникальности фраз в пределах одной группы допускается ввод только уникальных фраз (в случае нахождения полного дубликата операция редактирования будет отменена).
Для редактирования ячеек в остальных колонках можно поступить аналогичным образом. Однако в дополнение к этому также становится доступной контекстная вкладка«Таблица данных», где вы можете найти дополнительные инструменты для редактирования значений.
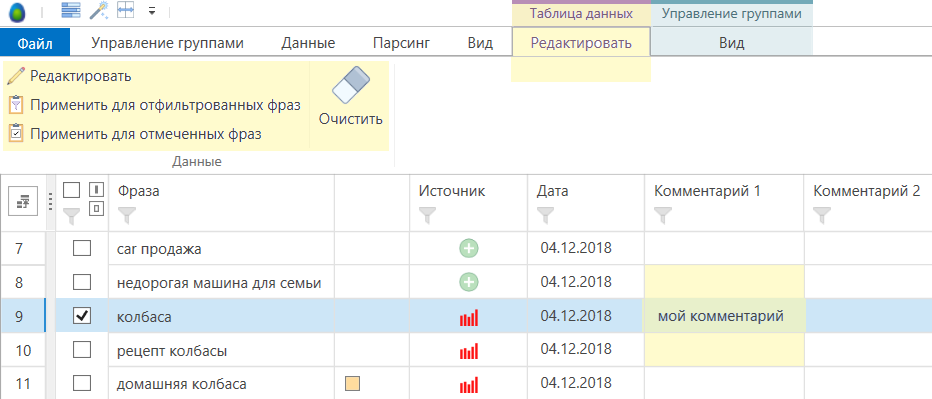
Вы можете изменить значения нескольких ячеек в одно действие. Для этого выделите ячейки и нажмите кнопку «Редактировать». В открывшемся диалоговом окне задайте желаемое значение и нажмите кнопку «OK».
О возможных последствиях и ответственности в результате использования Key Collector
Частью функциональностью программы Key Collector является взаимодействие со сторонними сервисами (сбор статистики, фраз и прочих данных по запросу пользователя).
При обращении к сторонним сервисам и ресурсам пользователь несет полную ответственность за взаимодействие с такими сервисами и ресурсами, которая может регулироваться как действующим законодательством Российской Федерации, действующим законодательством стран, резидентами которых являются эти сервисы, действующим законодательством стран, в которых зарегистрированы и/или ведут свою деятельность эти сервисы, так и условиями использования этих сервисов, различных соглашений между пользователем и этими сервисами, ресурсами.
Программа Key Collector является лишь клиентской программой, средством обращения к этим сервисам, ресурсам.
В силу технических особенностей взаимодействия со сторонними сервисами и ресурсами авторы Key Collector и владельцы торгового знака Key Collector не гарантируют полную работоспособность функций программы, напрямую или косвенно связанных со взаимодействием со сторонними сервисами, не несут ответственность за выполняемые пользователем программы действия, за возможный ущерб, полученный или нанесенный в результате использования программы.
Работа с пользовательскими группами
В Key Collector можно создавать пользовательские группы. Каждая группа будет содержать свою собственную таблицу с данными. Вы можете переносить или копировать ключевые слова из одной группы в другую с помощью специального инструмента.
Создание новой группы
Для создания новой группы можно воспользоваться одной из двух кнопок с изображением плюсика. Они находятся в панели управления. Или вы можете воспользоваться сочетанием быстрых клавиш Ctrl + T.

Создание новой группы
Если в вашем проекте группы имеют определенную вложенность, тогда новую группу можно создать сразу внутри другой группы. Для этого выделим первоначальную группу и нажмем на инструмент “Создать новую группу внутри”. Для удобства можете воспользоваться клавишами Ctrl + Shift + T
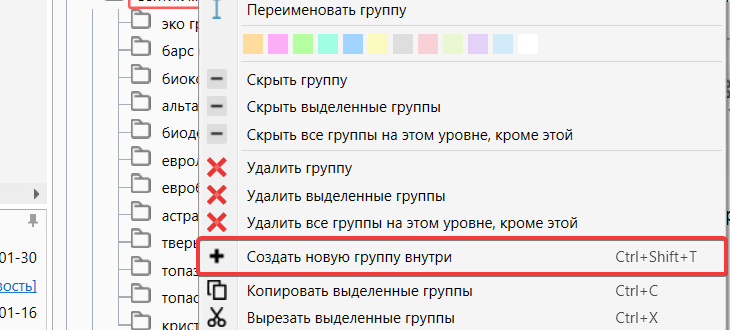
Создать новую группу внутри
Новую группу объявлений можно создать с помощью альтернативного способа. Для этого перейдем в раздел “Сбор данных”, после чего выбираем инструмент “Перенос фраз в другую группу” и в нем уже выбираем “Создать новую группу”

Создаем новую группу
Перемещение группы
В Key Collector реализован удобный механизм переноса групп. С помощью него можно выстроить такую цепочку вложенности, с которой удобнее всего работать. Для того, чтобы сделать надо выделить одну или несколько групп, зажать левую кнопку мышки и перенести в нужное место.
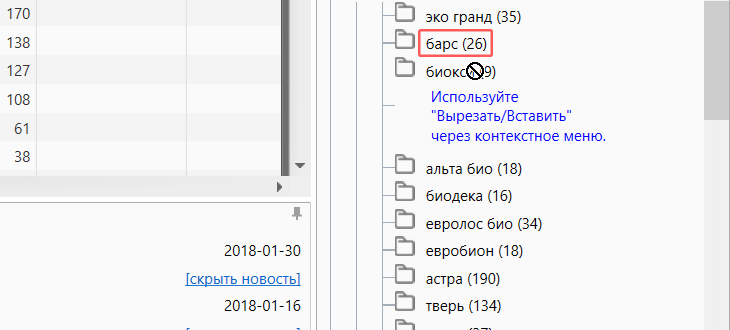
Перемещение группы
Переименование группы
Вы можете переименовать название групп. Для этого надо два раза кликнуть левой кнопкой мышки по ее заголовку. В появившейся строке задайте нужное имя. Для отмены можете нажать клавишу Esc, для сохранения изменений — клавишу Enter.
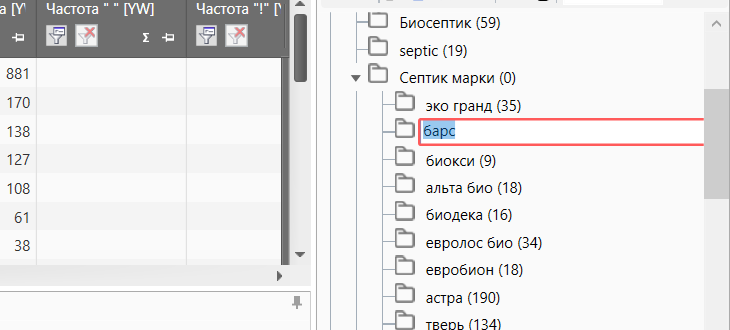
Переименование группы ч.1
Другим способом переименовать группу можно с помощью нажатия правой клавиши мышки и выбрать соответствующий пункт.

Переименование группы ч.2
Сортировка групп
В Key Collector можно сортировать группы используя названия или цвет заголовка.
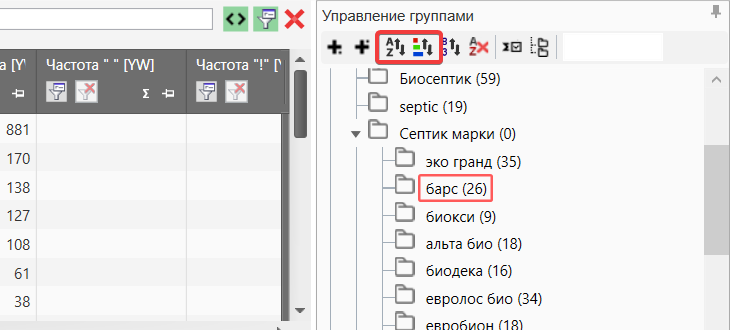
Сортировка групп
Данная функция находится в разделе управления группами. Очень удобный инструмент, если вы хотите сделать сортировку.
Удаление группы
Для того, чтобы удалить группы нужно выбрать соответствующий пункт, который показан на скриншоте ниже. Можно выделить несколько групп используя быстрые клавиши CTRL или SHIFT
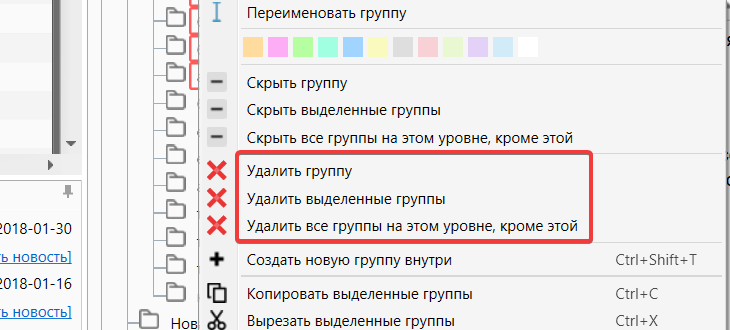
Удаление группы
Группы, которые вы удалите сперва будут скрыты. Данная функция полезна, если в процессе работы вы передумали удалять группу. Данные группы будут автоматически удалены по завершении работы Кей Коллектра.
Сокрытие группы
Для удобства реализована функция “Скрыть группы”. С помощью нее вы можете скрывать ненужные пользовательские группы.

Сокрытие группы
Для того, чтобы заново отобразить скрытые ранее группы, нужно нажать на иконку в разделе “Управления группами”.
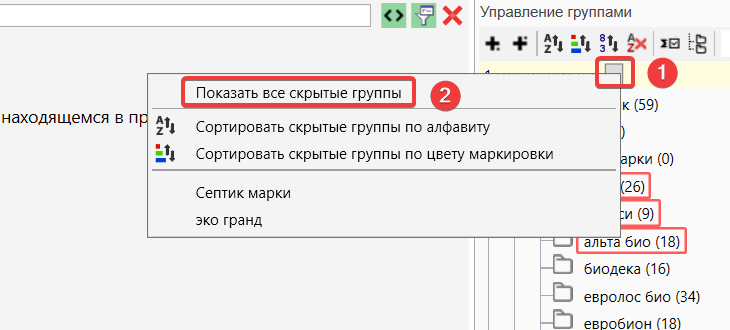
Показать все скрытые группы
Колорирование группы
Вы можете назначить для каждой группы свой цвет. Для этого надо выбрать соответствующий цвет в палитре расположенной в контекстном меню.Нажимаем правой кнопкой мышки на нужную группу и выбираем цвет.
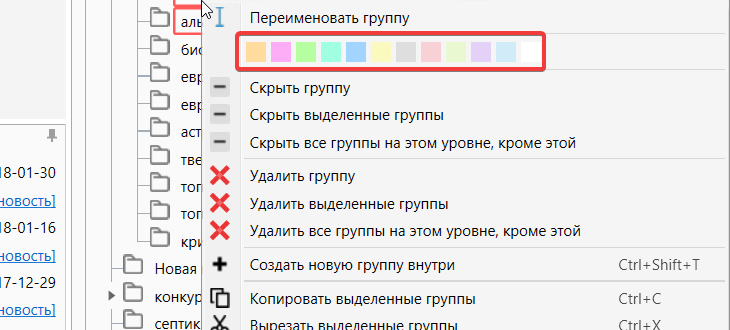
Колорирование группы
Работа с группировками запросов
Группировка запросов
После того, как запросы были кластеризованы (результат кластеризации будет виден все в той же левой панели программы), вы можете их экспортировать в файлы Excel и CSV формата.
Однако, как известно, какой бы качественной не была автоматическая группировка запросов, она все также будет нуждаться в «ручной» доработке, так как на данный момент, лучше человека понимать тонкости продвижения отдельных запросов и групп искусственный алгоритм еще не научился.
Дополнительно, в ручном режиме есть возможность посредством правой панели создавать произвольные группы любой вложенности и, таким образом, перенося в них кластеры из левой панели, создавать структуру вашего сайта прямо в программе с последующей возможностью экспорта итоговой структуры в Excel и сохранением форматирования относительно вложенности групп запросов.
Помимо переноса фраз, есть возможность удаления запросов, создание и переименование кластеров и групп.
Все эти манипуляции доступны через контекстное меню панелей группировки фраз.
Список стоп-слов
При помощи данного функционала можно выделять ключевые слова в левой или правой панели по определенным правилам и проводить над ними дальнейшие действия: удаление, перемещение и т.п.
Параметры действий при поиске запросов:
- Полное вхождение (ищем «я пил молоко», находим «молоко я пил вчера»).
- Частичное соответствие (ищем «ил моло», находим «я пил молоко»).
- Точное соответствие (ищем «я пил молоко», находим «я пил молоко»).
Это бывает удобно, например, для удаления ключевых слов из семантического ядра по списку стоп-слов, либо для поиска ключевых фраз по вхождению определенного слова, которые затем можно переместить в ту или иную группу.
Сортировка запросов и фильтрация
Отсортировать запросы можно при помощи нажатия на заголовки соответствующих столбцов. При нажатии на колонку «Частотность», запросы будут отсортированы по частоте запроса внутри каждой группы. Аналогично, при нажатии на заголовок колонки с запросами – они будут отсортированы по алфавиту. Группы запросов сортируются через пункт в контекстном меню.
Фильтрация данных позволяет фильтровать запросы по фразам, группам и частоте (если указана).
При фильтрации данных, найденные части слова из первого фильтра выделяются желтым цветом, а из второго – зеленым.
Переименование и цветовая маркировка
Для переименования группы дважды кликните по ее заголовку или воспользуйтесь соответствующим пунктом в контекстном меню.
Для массового редактирования заголовков можно воспользоваться функциями в меню «Формат заголовков» на вкладке «Управление группами».
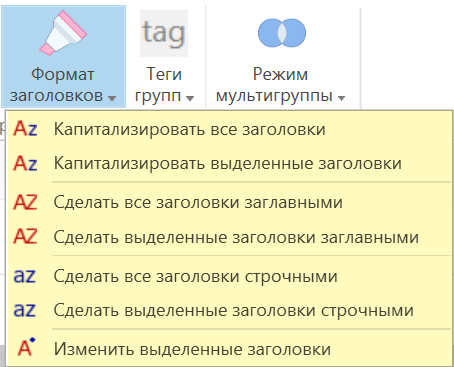
Вы также можете помечать цветами заголовки групп. Для пометки нескольких выделенных групп зажмите клавишу Ctrl.
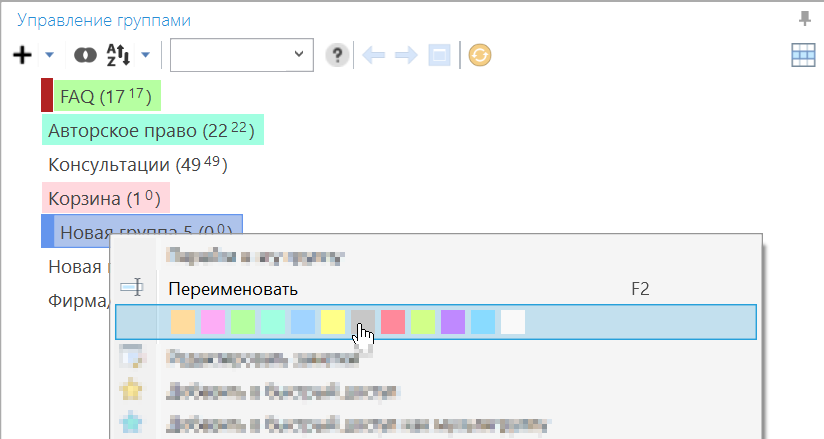
В «Настройках — Интерфейс — Управление группами» можно задать список цветов в формате цветов HTML (HEX ARGB).
Массовое переименование групп по маске
Функция изменения выделенных групп позволяет массово изменить заголовки выделенных групп по заданному пользователем шаблону. Например, можно не только назначить нескольким группам новый единый заголовок, но и сохранить в нем значения прошлых заголовков.
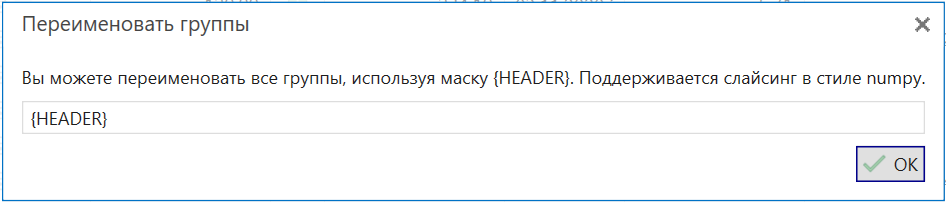
Группы «кастрюли», «сковородки», «чашки» могут быть переименованы в «кастрюли Москва», «сковородки Москва», «чашки Москва» (в существующему заголовку добавлено слово «Москва»). Или же можно выполнить замену части заголовка: «кабель 2.5», «провод 2.5» на «кабель 1.75», «провод 1.75» (выполнена замена 2.5 на 1.75).
Простые замены
Простая замена может использовать в маске макрос {HEADER}, который вставит на место {HEADER} прошлое значение заголовка группы.
Например, маска «купить {HEADER} Москва» превратит группы «носки», «колготки» в «купить носки Москва», «купить колготки Москва».
Слайсинг в стиле numpy
Помимо простой замены с сохранением полного прошлого заголовка иногда требуется модифицировать прошлый заголовок: отрезать какую-то его часть с начали или конца, использовать какую-то информацию из середины и т.п.
Для этих нужд используется широко известный синтаксис слайсинга в numpy (библиотека Python), поэтому если вы его освоите, то это пригодится не только при работе с Key Collector, но и для решения других задач.
Вы можете извлекать наборы символов (подстроки), задавая границы и длину строк с начала или с конца. Приведем несколько примеров.
Отрезать начало строки — {HEADER}N:
Можно указать индекс начала строки N с начала или с конца.
- {HEADER}4: — взять подстроку, начиная с 4-го символа с начала и до конца
- мск интернет —> интернет
- {HEADER}-5: — взять подстроку, начиная с 5-го символа с конца и до конца
-
блин 25 кг
—> 25 кг
Отрезать конец строки — {HEADER}:M
Можно указать индекс конца строки M с начала или с конца.
- {HEADER}:8 — взять подстроку, начиная с начала и до 8-го символа
- интернет мск —> интернет
- {HEADER}:-6 — взять подстроку, начиная с начала и заканчивая 6-м символом с конца
- саженцы москва —> саженцы
Взять из середины строки — {HEADER}N:M
Здесь можно указать индекс начала N и конца M подстроки. Аналогично можно указывать индексацию с начала или с конца строки, но индекс конца M должен быть расположен в абсолютном значении дальше индекса начала N.
- {HEADER}4:6 — взять подстроку, начиная с 4-го символа и заканчивая 6-м символом
- 122.65 частота —> 65
Функции замены
Поддерживается функция замены значения в заголовке на новое значение REPLACE(«old»;»new»). Использовать дополнительную индексацию или маску в параметрах функции не допускается (т.е. в кавычках должны быть заданы обычные слова или части слов.
- REPLACE(«мск»;»спб») — заменить в заголовке «мск» на «спб»
- ворота мск —> ворота спб
Также поддерживается расширенная функция замены по регулярному выражению REPLACERG(«pattern»;»replacement»). Опытные пользователи могут выполнять более сложные замены, используя синтаксис регулярных выражений.
Борьба с погрешностями и операторы поиска
К сожалению, при работе в формонезависимых режимах возможны погрешности. Иногда программа считает близкие по смыслу слова одинаковыми, а иногда наоборот не улавливает связи между одним и тем же словом в разных склонениях.
Специальными операторы поиска позволяются исправить ошибки или уточнить его критерии.
Фиксация словоформы (точный поиск)
Если программа ошибочно принимает какое-то слово за искомое, вы можете зафиксировать проблемное минус-слово оператором !
- !Киев
- !кий
- !как
- !тянули !репку
Например, «Киев» и «кий» в упрощенном быстром режиме могут считаться равными, т.к. их неизменяемая часть «ки» совпадает в обоих словах. Или же «как» и «почему» может быть приняты за равнозначные слова в улучшенном режиме.
Для фиксации минус-фразы необходимо использовать оператор ! перед каждым словом фразы. Фиксировать отдельные слова минус-фразы не допускается.
Фиксация фразы (фразовый поиск)
При поиске минус-фраз, состоящих из нескольких слов, по умолчанию программа разрешает присутствие посторонних слов между словами искомой фразы. Оператор » » локально запрещает эту возможность.
- «заказать торт»
- «в банке»
Например, минус-фраза заказать торт (без кавычек) будет найдена в запросе «заказать свадебный бисквитный торт с кремом». Если добавить оператор » «, то минус-фраза будет найдена только в запросах вида «заказать торт на праздник» (слова искомой фразы не разделены посторонними словами).
Фиксация порядка слов
- заказать торт
- в банке
Например, минус-фраза заказать торт (без кавычек) будет найдена в запросе «торт на праздник заказать». Если добавить оператор , то минус-фраза будет найдена только в запросах вида «заказать праздничный торт» (слова искомой фразы следуют строго в заданном порядке).
Композиция операторов
Допускается использование различных операторов сразу, однако важен порядок их применения.
- Фразовая фиксация » »
- Точная фиксация !
Сбор частот
Сбор частот позволяет оценить популярность запросов.
Сервис выдает кол-во показов запроса за последние 30 дней.
Статистика обновляется не ежедневно, поэтому не воспринимайте этот период буквально.
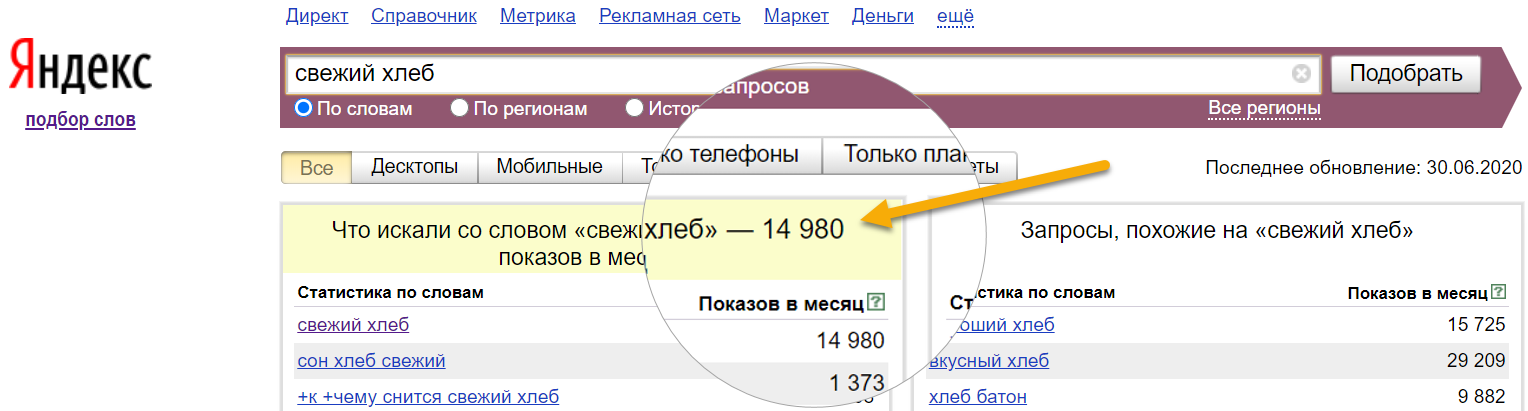
Сервис поддерживает различные операторы поиска, поэтому программа способна получать несколько видов частот.
Программа автоматически добавляет нужные операторы при сборе того или иного вида частот (добавлять операторы вручную к текст запросов не требуется).
Базовая частота
Базовая частота соответствует широкому типу вхождения слов. Для выполнения запроса достаточно отправить сам запрос в исходном виде:
- свежий хлеб
- условная вероятность
- теорема Байеса
В результатах могут быть учтены и другие фразы, косвенно относящиеся к запросу «свежий хлеб» в широком соответствии: купить свежий хлеб, свежий ржаной хлеб, рецепт хлеба, свежая выпечка и др.
Фразовая частота
Фразовая частота фиксирует состав слов в искомом запросе, и показы считаются для словосочетания целиком. Для выполнения запроса необходимо добавить двойные кавычки:
- «свежий хлеб»
- «теорема Байеса»
- «плотность распределения»
В результатах к запросу «свежий хлеб» будут учтены только фразы с тем же набором слов:: свежий хлеб, хлеба свежего и др.
Точная фразовая частота
Точная фразовая частота фиксирует не только состав, но и словоформы слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе и взять его в двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе: свежий хлеб, хлеб свежий (порядок не фиксируется).
Точная фразовая частота с порядком
Точная фразовая с порядком частота фиксирует состав, словоформы и порядок следования слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе, взять его в и двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе и том же порядке следования: свежий хлеб.
Частота по маске
Вы можете самостоятельно определить маску запроса, используя поддерживаемые сервисом операторы.
Маска запроса должна содержать фрагмент QUERY, который при сборе частот будет заменяться на текст исследуемого запроса.
Подбираем маски
Пробиваем маски через Wordstat и ищем похожие запросы.
Пример: собираем РК для бокс-клуба. Наши маски: «записаться на бокс», «занятия боксом» и т. д. Само слово «бокс» слишком широкое по смыслу. Включить его в нашу РК даже в точном соответствии нельзя. Но мы можем пробить слово «бокс» (уточнённое высокочастотными минус-словами) через Wordstat и найти ещё несколько масок, например, «абонемент на бокс», «тренера по боксу» и т. п.
За один год Uber потерял из-за мобильного фрода 100 млн $
Рассказываем, как мошенники убивают рекламные бюджеты и как защитить ваше приложение.
Спецпроект
Кроме того
-
Изучайте отчёты по реальным поисковым фразам в «Яндекс.Метрике» и Google AdWords.
-
Используйте сервисы подбора синонимов.
-
Пользуйтесь формулами сцепки в Excel или сервисами перемножения. Excel позволяет рассортировать все полученные маски «по полочкам», точнее, по столбикам. Сервис перемножения, наоборот, формирует единый столбец. Что удобнее — зависит от ситуации.
-
Используйте минус-слова уже на уровне масок для уточнения запросов. Например, мы собираем ядро для шкафов, предназначенных для разных помещений. Очевидные маски: «Шкаф гостиная», «Шкаф прихожая» и т. д. Но также можно пробить «Шкаф -духовой -холодильный» — этими минусами мы отсеем половину мусора уже на входе.
-
Пользуйтесь операторами «+» и «!», чтобы вытянуть большее количество слов из Wordstat. (Знак «!» фиксирует падеж и число слова, а «+» нужен для принудительного учёта предлогов и союзов.) По запросу с использованием операторов Wordstat выдаёт новую выборку, в которой могут оказаться и новые слова.
Пример: пробиваем маску «купить шкаф». Wordstat выдаёт фразы со следующей частотностью:
-
«купить шкаф» (100 000 показов);
-
«купить шкаф москва» (50 000 показов);
-
«купить шкаф недорого» (10 000 показов).
-
…
Далее пробиваем маску «Купить шкаф +в» — и тут Wordstat выдаёт новую картинку:
-
«купить шкаф +в» (70 000 показов);
-
«купить шкаф +в спальню» (40 000) показов;
-
…
Во вторую выборку попал запрос «купить шкаф +в спальню» (40 000 показов). Это вложенная фраза для «Купить шкаф». Судя по количеству показов, она должна оказаться в первой выборке между фразами «Купить шкаф москва» (50 000) и «Купить шкаф недорого» (10 000), но её там нет.
Заключение
Key Collector – сложная, многофункциональная утилита, которую вот так вот просто не освоить. Для более полного понимания чаще всего проходят специальное обучение. На курсах получают уроки по работе с семантикой и навыки по Кей Коллектору или аналогам. Поэтому сразу изучить эту программу полностью не получится.
Необходимый минимум в этой небольшой статье я вам дал. При помощи модуля Яндекс Вордстат вы сможете осуществлять съем семантического ядра, получать все виды частотностей и использовать это для составления крутых материалов. Имейте в виду, что сбор семантического ядра – работа тяжелая. Она требует серьезного подхода, и ни один инструмент не будет делать за вас абсолютно всю работу.
В случае с Кей Коллектором вам определенно придется покопаться с настройками. Многие пользователи изначально уделяют не так много времени этому, за что впоследствии расплачиваются неправильно составленной семантикой
Не совершайте ошибок, старайтесь уделить должное внимание настройкам и изучению особенностей работы этой утилиты
Если вы хотите разбираться не только в сборе семантического ядра, но еще и в создании крутых сайтов и их монетизации, я могу предложить вам пройти курс Василия Блинова “Как создать блог”. В нем будут рассмотрены все нюансы работы вебмастера, в том числе и такого аспекта, как сбор семантического ядра. По программе Key Collector вы тоже пройдетесь, получив более полные знания о работе в нем. Доступ на первый уровень предоставляется абсолютно бесплатно, поэтому не упустите свой шанс.
Вывод
Кей Коллектор — это непростой и мультифункциональный инструмент, который не получится освоить за один день при всем желании. Как правило, для углубленного понимания функционала программы и порядка применения опций, пользователи проходят определенные курсы по обучению или тратят несколько недель на изучение всех тонкостей по работе с сервисом.
В основном, данную программу используют в сборе семантики для дальнейшего SEO-продвижения сайта или его страниц, а также, для настройки контекстной рекламы.
Мы постарались дать вам базовые знания по использованию этого парсера на основе простых примеров. Точнее говоря, мы продемонстрировали примерно 15% от всего функционала. Дальше «дело за вами». Но сбор семантики — это непростая работа, требующая существенных затрат времени и сил, поскольку ни один сервис не станет выполнять за вас абсолютно все.
Рассматривая КК, вам придется потратить немало времени на его настройку. Ошибка некоторых людей в том, что первоначально они не удаляют внимания этому и, в результате, имеют неправильно собранное семантическое ядро. Поэтому мы рекомендуем вам не наступать на грабли множества своих предшественников, а потратить чуть больше времени и сил на изучение тонкостей этой программы. Если у вас остались вопросы по прочитанному материалу или вы хотите поделиться своим мнением по данной статье, напишите нам в комментарии, и мы обязательно вам ответим.






