Метод split()
Содержание:
- # API
- Срезы строк
- Форматирование строки
- 구문
- # Installation
- Добавление/удаление элементов
- Did You Know?
- # Get Started
- Добавление элементов
- Split ( )
- Описание
- Поиск в массиве
- Токенизация с использованием RegEx(регулярных выражений) в Python
- Метод split()
- Production[edit | edit source]
- # Упражнения
- Токенизация с набором инструментов естественного языка
- Итого
# API
Options
| Options | Description |
|---|---|
| An optional list of elements or a css selector. By default, this is | |
| The splitting plugin to use. See the plugin page for a full list. If not specified, the value of the data-splitting attribute will be use. If that is not present, the plugin will be used. | |
| An optional key used as a prefix on on CSS Variables. For instance when a key of is used with the plugin, it will changethe CSS variable to . This should be used if multiple splits have been performed on the same element, or to resolve conflicts with other libraries. |
Plugin-specific Options
| Options | Description |
|---|---|
| Used by the following plugins to select children to index: , , , , , , and . If not specified, the immediate child elements will be selected. | |
| The number of columns to create or detect. This is used by the following plugins: , , , and | |
| The number of rows to create or detect. This is used by the following plugins: , , , and | |
| If true, the plugin will count whitespace while indexing characters. |
Returns
The fucntion always returns an array of objects with the following properties based on plugin name, giving you access to each element’s splits to use with JavaScript animation libraries or for additional processing.
| Property | Type | Description |
|---|---|---|
| An array of all characters created by the plugin | ||
| An array of all words created by the and plugin | ||
| An array of element arrays by the line, returned by the plugin | ||
| An array of elements returned by the plugin. | ||
| An array of element arrays by row, returned by the and plugin | ||
| An array of element arrays by column, returned by the and plugin | ||
| An array of cells created by , , or plugin | ||
| An array of element arrays by the row, returned by the and plugin | ||
| An array of element arrays by the column, returned by the and plugin |
The function takes the same options as but has a required property of . The property should be an html string to be used as the splitting target. The function returns a string of the rendered HTML instead of returning a result object. This function is intended to be used inside of JS Framework DSL’s such as the Vue templating language:
| Options | Description |
|---|---|
| The name of the plugin. It must be unique. | |
| The prefix to set when adding index/total css custom properties to the elements. | |
| The function to call when this plugin is used. The return value is set in the result of as the same name as the in the plugin. | |
| The plugins that must run prior to this plugin. |
Срезы строк
В Python также можно получать срезы строк. То есть, вытащить подстроку из строки по первому и последнему индексу (или только по первому или последнему).
Чтобы это было более просто понять, давайте приведем пример.
Допустим, у нас есть строка s, которая содержит значение «python». Если мы сделаем срез, начиная с элемента со вторым индексом и с пятым индексом, то вывод интерпретатора будет содержать фразу «tho».
Почему так? Дело в том, что в случае со срезами строк индексы точно так же, учитываются с нуля. Поэтому первое значение по факту является нулевым. Второе же значение должно записываться, как следующее, которое идет за тем, который нам надо получить последним.
То есть, принцип такой. Первое число должно являть собой индекс по системе нумерации Python, а второе – по стандартной порядковой системе.
В нашем случае – первый символ считаем от 0, и для получения третьего знака необходимо написать индекс 2, а для получения последнего знака необходимо отсчет вести от единицы.
Если этот принцип покажется нелогичным, то вот более простая формула для наглядности. Срез строки возвращает количество символов, равное второму индексу – первому.
Давайте для наглядности приведем пример.
>>> s = ‘python’
>>> s
‘tho’
Количество символов, начиная от первого индекса считается следующим образом:
- Интерпретатор находит символ с индексом 2 (то есть, буква p).
- После этого от 5 отнимает 2. Получается 3.
- И интерпретатор отсчитывает три символа, при этом первый включается.
Если отпустить первый индекс, то он считается началом строки.
Соответственно, если опустить второй индекс, то достаются все символы, начиная первым индексом, и до конца строки.
>>> s = ‘python’
>>> s
‘pyth’
>>> s
‘pyth’
>>> s = ‘python’
>>> s
‘thon’
>>> s
‘thon’
Можно также пропустить оба индекса. В этом случае мы получаем полную строку.
>>> s = ‘python’
>>> t = s
>>> id(s)
59598496
>>> id(t)
59598496
>>> s is t
True
Также со срезами можно использовать отрицательные индексы.
Шаг для среза строки
Также можно добавить третий индекс через двоеточие. Таким образом программист задает шаг для среза. То есть, через сколько символов должны отбираться символы строки. Например, если использовать строку python и использовать индексы 0:6:2, то тогда отбор осуществляется, начиная первым символом по счету и заканчивая шестым по счету. При этом каждый второй символ не учитывается.
Теперь давайте приведем код для наглядности.
>>> s = ‘foobar’
>>> s
‘foa’
>>> s
‘obr’
Если задается шаг, то первый и второй индекс также можно не использовать. Соответственно, срез начинается с самого начала или с определенного момента до самого конца, но при этом значения пропускаются в соответствии с тем индексом, который указан третьим по счету.
Например, так.
>>> s = ‘12345’ * 5
>>> s
‘1234512345123451234512345’
>>> s
‘11111’
>>> s
‘55555’
Значение шага может быть и отрицательным. В этом случае интерпретатор начинает концом строки. При этом начальный индекс должен быть больше второго.
>>> s = ‘python’
>>> s
‘nhy’
В этом примере индексы 5:0:-2 означают следующее: интерпретатор начинает последним символом, не включая первый символ, но при этом делает два шага назад.
Если первый и второй индексы пропускаются при ходе назад, значения по умолчанию считаются следующим образом. Первый индекс указывает на окончание строчки, в то время как второй – на ее начало.
Чтобы эту закономерность понять более глубоко, приведем пример.
>>> s = ‘12345’ * 5
>>> s
‘1234512345123451234512345’
>>> s
‘55555’
А теперь задачка. Попробуйте, основываясь на полученной информации, развернуть строку так, чтобы первая буква была первой, вторая – второй.
А теперь проверьте свой ответ.
>>> s = ‘Если так говорит товарищ Наполеон, значит, так оно и есть.’
>>> s
‘.ьтсе и оно кат ,тичанз ,ноелопаН щиравот тировог кат илсЕ’
Форматирование строки
Как правильно в Python указывать комбинацию строк и числовых переменных, например, при выводе в консоль? Код будет приблизительно следующим.
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print(‘Произведение’, n, ‘на’, m, ‘равно’, prod)
Произведение 20 на 25 равно 500
Недостаток такого подхода в том, что приходится много ставить кавычек, запятых. В целом, это сильно тормозит написание кода, а также добавляет сложностей при его чтении. Чтобы решить эту проблему, в Python добавили функцию, которая называется литералом отформатированной строки.
Она впервые появилась в 3,6 версии этого языка. Ее также часто называют f-string.
В целом, функционал этого инструмента просто невероятен, поэтому его надо рассматривать отдельно.
Но мы расскажем, как его реализовывать для интерполяции переменной. Можно непосредственно ее указать в f-строковом литерале, и Python автоматически подставит подходящее значение.
Вот так будет выглядеть код, выполняющий аналогичные действия, но с использованием f-string.
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print(f’Произведение {n} на {m} равно {prod}’)
Произведение 20 на 25 равно 500
Последняя строка в нашем примере – это наглядная демонстрация того результата, который будет в строке вывода.
Исходя из этого, сформулируем правила использования f-строк.
- Перед кавычками необходимо написать букву f. Так интерпретатор поймет, что необходимо использовать f-строки.
- Введите те переменные, которые необходимо использовать, предварительно заключив их в фигурные скобки {}.
С буквой f можно использовать любые кавычки.
Изменение строк
Изначально Python не предусматривает возможности изменения строк. То есть, нельзя просто взять и заменить отдельный ее элемент. В этом случае будет выдана ошибка
TypeError: ‘str’ object does not support item assignment
Тем не менее, в этом нет никакой проблемы. Просто технически изменение строки являет собой создание копии строки с нужными изменениями, а потом осуществление перезаписи той переменной, где была старая строка. Python это позволяет сделать в два способа.
Есть два способа, как можно добиться этой задачи. Например, этот.
>>> s = s + ‘t’ + s
>>> s
‘pytton’
Или же можно воспользоваться методом string.replace(x,y).
Этот метод находит подстроку в первом аргументе и заменяет эту часть на содержимое второго аргумента.
>>> s = ‘python’
>>> s = s.replace(‘h’, ‘t’)
>>> s
‘pytton’
А теперь более подробно рассмотрим, что такое методы и как для чего они нужны при работе со строками.
구문
str.split([separator[, limit]])
주의: 구분자로 빈 문자열()을 제공하면, 사용자가 인식하는 문자 하나() 또는 유니코드 문자(코드포인트) 하나씩으로 나누는 것이 아니라, UTF-16 코드유닛으로 나누게 되며 surrogate pair가 망가질 수 있습니다. 스택 오버플로우의 How do you get a string to a character array in JavaScript? 질문도 참고해 보세요.
매개변수
- Optional
- 원본 문자열을 끊어야 할 부분을 나타내는 문자열을 나타냅니다. 실제 문자열이나 정규표현식을 받을 수 있습니다. 문자열 유형의 가 두 글자 이상일 경우 그 부분 문자열 전체가 일치해야 끊어집니다. 가 생략되거나 에 등장하지 않을 경우, 반환되는 배열은 원본 문자열을 유일한 원소로 가집니다. 가 빈 문자열일 경우 의 각각의 문자가 배열의 원소 하나씩으로 변환됩니다.
- Optional
-
끊어진 문자열의 최대 개수를 나타내는 정수입니다. 이 매개변수를 전달하면 split() 메서드는 주어진 가 등장할 때마다 문자열을 끊지만 배열의 원소가 개가 되면 멈춥니다. 지정된 한계에 도달하기 전에 문자열의 끝까지 탐색했을 경우 개 미만의 원소가 있을 수도 있습니다. 남은 문자열은 새로운 배열에 포함되지 않습니다.
# Installation
Why bother with build systems or files? Use the CodePen Template to make your own Splitting demo!
Using NPM
Install Splitting from NPM:
Import Splitting from the package and call it. The CSS imports may vary depending on your bundler.
Using a CDN
TIP
CDN use is only recommended for demos / experiments on platforms like CodePen. For production use, bundle Splitting using the with Webpack or your preferred code bundler.
You can get the latest version of Splitting off of the unpkg CDN and include the necessary files as follows.
Then call Splitting on document load/ready or in a script at the bottom the of the .
Recommended Styles
Included in the package are two small stylesheets of recommended CSS that will make text and grid based effects much easier. These styles are non-essential, but provide a lot of value.
- includes many extra CSS Variables and psuedo elements that help power advanced animations, especially for text.
- contain the basic setup styles for cell/grid based effects you’d otherwise need to implement yourself.
Browser Support
Splitting should be thought of as a progressive enhancer. The basic functions work in any halfway decent browser (IE11+). Browsers that support CSS Variables ( ) will have the best experience. Browsers without CSS Variable support can still have a nice experience with at least some animation, but features like index-based staggering may not be feasible without JavaScript.
The styles in for the rely on , so there may be additional browser limitations. In general, so you should be in the clear.
Добавление/удаление элементов
Мы уже знаем методы, которые добавляют и удаляют элементы из начала или конца:
- – добавляет элементы в конец,
- – извлекает элемент из конца,
- – извлекает элемент из начала,
- – добавляет элементы в начало.
Есть и другие.
Как удалить элемент из массива?
Так как массивы – это объекты, то можно попробовать :
Вроде бы, элемент и был удалён, но при проверке оказывается, что массив всё ещё имеет 3 элемента .
Это нормально, потому что всё, что делает – это удаляет значение с данным ключом . Это нормально для объектов, но для массивов мы обычно хотим, чтобы оставшиеся элементы сдвинулись и заняли освободившееся место. Мы ждём, что массив станет короче.
Поэтому для этого нужно использовать специальные методы.
Метод arr.splice(str) – это универсальный «швейцарский нож» для работы с массивами. Умеет всё: добавлять, удалять и заменять элементы.
Его синтаксис:
Он начинает с позиции , удаляет элементов и вставляет на их место. Возвращает массив из удалённых элементов.
Этот метод проще всего понять, рассмотрев примеры.
Начнём с удаления:
Легко, правда? Начиная с позиции , он убрал элемент.
В следующем примере мы удалим 3 элемента и заменим их двумя другими.
Здесь видно, что возвращает массив из удалённых элементов:
Метод также может вставлять элементы без удаления, для этого достаточно установить в :
Отрицательные индексы разрешены
В этом и в других методах массива допускается использование отрицательного индекса. Он позволяет начать отсчёт элементов с конца, как тут:
Метод arr.slice намного проще, чем похожий на него .
Его синтаксис:
Он возвращает новый массив, в который копирует элементы, начиная с индекса и до (не включая ). Оба индекса и могут быть отрицательными. В таком случае отсчёт будет осуществляться с конца массива.
Это похоже на строковый метод , но вместо подстрок возвращает подмассивы.
Например:
Можно вызвать и вообще без аргументов: создаёт копию массива . Это часто используют, чтобы создать копию массива для дальнейших преобразований, которые не должны менять исходный массив.
Метод arr.concat создаёт новый массив, в который копирует данные из других массивов и дополнительные значения.
Его синтаксис:
Он принимает любое количество аргументов, которые могут быть как массивами, так и простыми значениями.
В результате мы получаем новый массив, включающий в себя элементы из , а также , и так далее…
Если аргумент – массив, то все его элементы копируются. Иначе скопируется сам аргумент.
Например:
Обычно он просто копирует элементы из массивов. Другие объекты, даже если они выглядят как массивы, добавляются как есть:
…Но если объект имеет специальное свойство , то он обрабатывается как массив: вместо него добавляются его числовые свойства.
Для корректной обработки в объекте должны быть числовые свойства и :
Did You Know?
Trivia
On Kevin’s computer, there are QuickTime files of his various personalities. The one in the bottom right corner is Mr. Pritchard. This is likely a reference to the character Lionel Pritchard from Знаки (2002), also directed by M. Night Shyamalan. See more »
Goofs
When the camera approaches the father putting food in the trunk, you can see the camera crew’s legs in the reflection in the fender of the car. See more »
Quotes
Claire Benoit:
That’s what happens when you do a mercy invite.
Mr. Benoit:
I believed you wanted to invite everyone.
Claire Benoit:
Dad, I can’t invite everyone in my art class except for one person without social networking evidence inflicting more pain on that person than was intended. And I’m not a monster.
Mr. Benoit:
I’m proud of you. I think.
Claire Benoit:
She gets detention a lot and she yells at teachers sometimes. There was that rumor that went around that she just kept running away from home.
Marcia:
Um, maybe …
See more »
Crazy Credits
The end credits are shown in 24 frames in the background of the scrolling credits to simulate the 24 different personalities that Kevin has in the movie. See more »
# Get Started
Start playing around with your own Splitting demo on CodePen with this template that includes all of the essentials!
Basic Usage
Splitting can be called without parameters, automatically splitting all elements with attributes by the default of which wraps the element’s text in s with relevant CSS vars.
Initial DOM
DOM Output
The aftermath may seem verbose, but this won’t be visible to the end user. They’ll still just see «ABC», but now you can style, animate and transition all of those characters individually!
Splitting will automatically add a class to the targetted element after it’s been run. Each will add their own classes to splits/parent as needed ( for , for , etc. ).
Добавление элементов
Чтобы добавить элементы с помощью splice ( ), необходимо ввести их в качестве третьего, четвертого и пятого элемента (в зависимости от того, сколько элементов нужно добавить):
array.splice(index, number of elements, element, element);
В качестве примера, добавим элементы a и b в самое начало массива:
array.splice(0, 0, 'a', 'b');
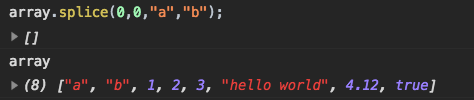
Элементы a и b добавлены в начало массива
Split ( )
Методы Slice( ) и splice( ) используются для массивов. Метод split( ) используется для строк. Он разделяет строку на подстроки и возвращает их в виде массива. У этого метода 2 параметра, и оба из них не обязательно указывать.
string.split(separator, limit);
- Separator: определяет, как строка будет поделена на подстроки: запятой, знаком и т.д.
- Limit: ограничивает количество подстрок заданным числом
Метод split( ) не работает напрямую с массивами. Тем не менее, сначала можно преобразовать элементы массива в строки и уже после применить метод split( ).
Давайте посмотрим, как это работает.
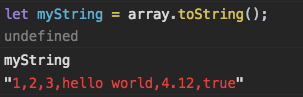
Сначала преобразуем массив в строку с помощью метода toString( ):
let myString = array.toString();
Затем разделим строку myString запятыми и ограничим количество подстрок до трех. Затем преобразуем строки в массив:
let newArray = myString.split(",", 3);
В виде массива вернулись первые 3 элемента
Таким образом, элементы массива myString разделены запятыми. Мы поставили ограничение в 3 подстроки, поэтому в качестве массива вернулись первые 3 элемента.

Все символы разделены на подстроки
Описание
Метод split() используется для разбиения строки на массив подстрок и возвращает новый массив.
Если разделитель separator найден, он удаляется из строки, а подстроки возвращаются в массиве. Следует
отметить, что если разделитель separator соответствует началу строки, первый элемент возвращаемого массива будет пустой строкой – текстом, присутствующим перед разделителем separator. Аналогично, если разделитель соответствует концу строки, последний элемент массива (если это не противоречит значению аргумента limit) будет пустой строкой.
Если разделитель separator опущен, строка вообще не разбивается, и возвращаемый массив содержит только один строковый элемент, представляющий собой строку целиком.
Если разделитель представляет собой пустую строку «» или регулярное выражение, соответствующее пустой строке, то строка разбивается между каждым символом, а возвращаемый массив имеет ту же длину, что и исходная строка.
Если разделитель separator – это регулярное выражение, содержащее подвыражения в скобках, то подстроки, соответствующие этим подвыражениям (кроме текста, соответствующего регулярному выражению в целом), включаются в возвращаемый массив.
Примечание: Если строка является пустой строкой, метод split() вернёт массив, состоящий из одной пустой строки, а не пустой массив.
С этим читают
Поиск в массиве
Далее рассмотрим методы, которые помогут найти что-нибудь в массиве.
Методы arr.indexOf, arr.lastIndexOf и arr.includes имеют одинаковый синтаксис и делают по сути то же самое, что и их строковые аналоги, но работают с элементами вместо символов:
- ищет , начиная с индекса , и возвращает индекс, на котором был найден искомый элемент, в противном случае .
- – то же самое, но ищет справа налево.
- – ищет , начиная с индекса , и возвращает , если поиск успешен.
Например:
Обратите внимание, что методы используют строгое сравнение. Таким образом, если мы ищем , он находит именно , а не ноль. Если мы хотим проверить наличие элемента, и нет необходимости знать его точный индекс, тогда предпочтительным является
Если мы хотим проверить наличие элемента, и нет необходимости знать его точный индекс, тогда предпочтительным является .
Кроме того, очень незначительным отличием является то, что он правильно обрабатывает в отличие от :
Представьте, что у нас есть массив объектов. Как нам найти объект с определённым условием?
Здесь пригодится метод arr.find.
Его синтаксис таков:
Функция вызывается по очереди для каждого элемента массива:
- – очередной элемент.
- – его индекс.
- – сам массив.
Если функция возвращает , поиск прерывается и возвращается . Если ничего не найдено, возвращается .
Например, у нас есть массив пользователей, каждый из которых имеет поля и . Попробуем найти того, кто с :
В реальной жизни массивы объектов – обычное дело, поэтому метод крайне полезен.
Обратите внимание, что в данном примере мы передаём функцию , с одним аргументом. Это типично, дополнительные аргументы этой функции используются редко. Метод arr.findIndex – по сути, то же самое, но возвращает индекс, на котором был найден элемент, а не сам элемент, и , если ничего не найдено
Метод arr.findIndex – по сути, то же самое, но возвращает индекс, на котором был найден элемент, а не сам элемент, и , если ничего не найдено.
Метод ищет один (первый попавшийся) элемент, на котором функция-колбэк вернёт .
На тот случай, если найденных элементов может быть много, предусмотрен метод arr.filter(fn).
Синтаксис этого метода схож с , но возвращает массив из всех подходящих элементов:
Например:
Токенизация с использованием RegEx(регулярных выражений) в Python
Прежде чем перейти к следующему методу, давайте вкратце разберемся с регулярным выражением. Регулярное выражение, также известное как RegEx, представляет собой особую последовательность символов, которая позволяет пользователям находить или сопоставлять другие строки или наборы строк с помощью этой последовательности в качестве шаблона.
Чтобы начать работу с RegEx в Python предоставляет библиотеку, известную как re. Библиотека re – одна из предустановленных библиотек в Python.
Пример 2.1: Токенизация Word с использованием метода RegEx в Python
import re my_text = """Joseph Arthur was a young businessman. He was one of the shareholders at Ryan Cloud's Start-Up with James Foster and George Wilson. The Start-Up took its flight in the mid-90s and became one of the biggest firms in the United States of America. The business was expanded in all major sectors of livelihood, starting from Personal Care to Transportation by the end of 2000. Joseph was used to be a good friend of Ryan.""" my_tokens = re.findall
Выход:
Объяснение:
В приведенном выше примере мы импортировали библиотеку re, чтобы использовать ее функции. Затем мы использовали функцию findall() библиотеки re. Эта функция помогает пользователям найти все слова, соответствующие шаблону, представленному в параметре, и сохранить их в списке.
Кроме того, “\ w” используется для обозначения любого символа слова, относится к буквенно-цифровому (включая буквы, числа) и подчеркиванию(_). «+» обозначает любую частоту. Таким образом, мы следовали шаблону +, так что программа должна искать и находить все буквенно-цифровые символы, пока не встретит какой-либо другой.
Теперь давайте посмотрим на токенизацию предложения с помощью метода RegEx.
Пример 2.2: Токенизация предложения с использованием метода RegEx в Python
import re
my_text = """The Advertisement was telecasted nationwide, and the product was sold in around 30 states of America. The product became so successful among the people that the production was increased. Two new plant sites were finalized, and the construction was started. Now, The Cloud Enterprise became one of America's biggest firms and the mass producer in all major sectors, from transportation to personal care. Director of The Cloud Enterprise, Ryan Cloud, was now started getting interviewed over his success stories. Many popular magazines were started publishing Critiques about him."""
my_sentences = re.compile(' ').split(my_text)
print(my_sentences)
Выход:
Объяснение:
В приведенном выше примере мы использовали функцию compile() библиотеки re с параметром ‘’ И использовали метод split() для отделения строки от указанного разделителя. В результате программа разбивает предложения, как только встречает любой из этих символов.
Метод split()
Когда вам нужно разбить строку на подстроки, вы можете использовать метод split().
Метод split() принимает строку и возвращает список подстрок. Синтаксис данного метода выглядит следующим образом:
Здесь – любая допустимая строка в Python, а – это разделитель, по которому вы хотите разделить исходную строку. Его следует указывать в виде строки.
Например, если вы хотите разделить по запятым, нужно установить .
– необязательный аргумент. По умолчанию метод split() разбивает строки по пробелам.
– еще один опциональный аргумент, указывающий, сколько раз вы хотите разделить исходную строку . По умолчанию имеет значение -1. При таком значении метод разбивает строку по всем вхождениям параметра sep.
Если вы хотите разделить исходную строку на две части, по первому вхождению запятой, вы можете установить . Так вы получите две подстроки: части исходной строки до и после первой запятой.
Таким образом, при одном разрезе строки вы получаете 2 подстроки. При двух разрезах — 3 подстроки. то есть, разрезая строку k раз, вы получите k+1 фрагментов.
Давайте рассмотрим несколько примеров, чтобы увидеть метод split() в действии.
Примеры использования метода split() в Python
Зададим строку , как это показанного ниже. После этого вызовем метод split() для без аргументов и .
my_string = "I code for 2 hours everyday" my_string.split() #
Вы можете видеть, что разделена по всем пробелам. Метод возвращает список подстрок.
Рассмотрим следующий пример. Здесь содержит названия фруктов, разделенные запятыми.
Давайте разделим по запятым. Для этого нужно установить или просто передать в метод при вызове.
my_string = "Apples,Oranges,Pears,Bananas,Berries"
my_string.split(",")
#
Как и ожидалось, метод split() вернул список фруктов, где каждый фрукт из стал элементом списка.
Теперь давайте воспользуемся необязательным аргументом и установив его равным 2.
my_string.split(",", 2)
#
Попробуем разобрать получившийся список.
Напомним, что , и мы решили разделить эту строку по запятым .
Первая запятая стоит после , и после первого разделения у нас будет две подстроки: и .
Вторая запятая стоит после . Таким образом, после второго деления у нас будет уже три подстроки: , и .
Сделав два разреза строки, мы достигли установленного максимума, и дальнейшее деление невозможно. Поэтому часть строки после второй запятой объединяется в один элемент в возвращаемом списке.
Надеюсь, теперь вы понимаете, как работает метод split() и для чего нужны аргументы и .
Production[edit | edit source]
Shyamalan conceived the idea for Split years before he actually wrote the screenplay. He explained, «In this case I had written the character a while ago, and I had written out a few scenes of it, so I even had dialogue written out, which is really unusual for me. It sat there for a long time, and I really don’t have a clear reason why I didn’t pull the trigger earlier. But this felt like the perfect time to do it, with the type of movies I’m doing now, and the type of tones I am interested in – humor and suspense.
On October 2, 2015, James McAvoy was cast in the film to play the lead, replacing Joaquin Phoenix. On October 12, 2015, Anya Taylor-Joy, Betty Buckley, Jessica Sula, and Haley Lu Richardson were added to the cast. On October 27, 2015, Universal Pictures came on board to release the film and titled it as Split.
Principal photography on the film began on November 11, 2015, in Philadelphia, Pennsylvania. Reshoots occurred in June 2016. During post-production, Sterling K. Brown’s role as Shaw, Dr. Fletcher’s neighbor, was cut from the film, as Shyamalan felt that his scenes were ultimately unnecessary.
# Упражнения
- Это код Виты, который вы последовательно писали на протяжении нескольких тем. Можете запустить его, вспомнить как выполняются запросы из списка .
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849
А. Отредактируйте список запросов queries. Все запросы должны начинаться с обращения Вита:
- Вита, сколько у меня друзей?
- …
Б. Напишите функцию . Значение параметра должно быть обработано методом . Отделите имя в начале от тела запроса (т.е., от оставшейся части).
Если запрос начинается с имени «Вита», то вызовите функцию , передав в неё тело запроса как параметр. И верните результат выполнения этой функции. Если запрос начинается с другого имени, то пока ничего не делайте — это отложим до следующей задачи.
В. Измените в функции вызов на вызов .
- А. Напишите функцию (англ. friend, «друг»), принимающую имя друга и запрос .
- Если друга с указанным именем нет в списке, то функция должна вернуть сообщение об ошибке .
- Если запрос — «ты где?», то функция должна вернуть сообщения ‘Н в городе Г’, где Г определяется по данным словаря .
- Если запрос не «ты где?», а какой-то другой, то функция должна вернуть сообщение об ошибке <неизвестный запрос>.
Б. Допишите функцию . Если запрос начинается не с «Вита», а с другого имени, то вызовите функцию , передав в неё имя друга и тело запроса. И верните результат выполнения этой функции.
В. Добавьте в список новые запросы вида:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152
Токенизация с набором инструментов естественного языка
Набор инструментов для естественного языка, также известный как NLTK, – это библиотека, написанная на Python. Библиотека NLTK обычно используется для символьной и статистической обработки естественного языка и хорошо работает с текстовыми данными.
Набор инструментов для естественного языка(NLTK) – это сторонняя библиотека, которую можно установить с помощью следующего синтаксиса в командной оболочке или терминале:
$ pip install --user -U nltk
Чтобы проверить установку, можно импортировать библиотеку nltk в программу и выполнить ее, как показано ниже:
import nltk
Если программа не выдает ошибку, значит, библиотека установлена успешно. В противном случае рекомендуется повторить описанную выше процедуру установки еще раз и прочитать официальную документацию для получения более подробной информации.
В наборе средств естественного языка(NLTK) есть модуль с именем tokenize(). Этот модуль далее подразделяется на две подкатегории: токенизация слов и токенизация предложений.
- Word Tokenize: метод word_tokenize() используется для разделения строки на токены или слова.
- Sentence Tokenize: метод sent_tokenize() используется для разделения строки или абзаца на предложения.
Давайте рассмотрим пример, основанный на этих двух методах:
Пример 3.1: Токенизация Word с использованием библиотеки NLTK в Python
from nltk.tokenize import word_tokenize my_text = """The Advertisement was telecasted nationwide, and the product was sold in around 30 states of America. The product became so successful among the people that the production was increased. Two new plant sites were finalized, and the construction was started. Now, The Cloud Enterprise became one of America's biggest firms and the mass producer in all major sectors, from transportation to personal care. Director of The Cloud Enterprise, Ryan Cloud, was now started getting interviewed over his success stories. Many popular magazines were started publishing Critiques about him.""" print(word_tokenize(my_text))
Выход:
Объяснение:
В приведенной выше программе мы импортировали метод word_tokenize() из модуля tokenize библиотеки NLTK. Таким образом, в результате метод разбил строку на разные токены и сохранил ее в списке. И, наконец, мы распечатали список. Более того, этот метод включает точки и другие знаки препинания как отдельный токен.
Пример 3.1: Токенизация предложения с использованием библиотеки NLTK в Python
from nltk.tokenize import sent_tokenize my_text = """The Advertisement was telecasted nationwide, and the product was sold in around 30 states of America. The product became so successful among the people that the production was increased. Two new plant sites were finalized, and the construction was started. Now, The Cloud Enterprise became one of America's biggest firms and the mass producer in all major sectors, from transportation to personal care. Director of The Cloud Enterprise, Ryan Cloud, was now started getting interviewed over his success stories. Many popular magazines were started publishing Critiques about him.""" print(sent_tokenize(my_text))
Выход:
Объяснение:
В приведенной выше программе мы импортировали метод sent_tokenize() из модуля tokenize библиотеки NLTK. Таким образом, в результате метод разбил абзац на разные предложения и сохранил его в списке. Затем мы распечатали список.
Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Итого
Шпаргалка по методам массива:
-
Для добавления/удаления элементов:
- – добавляет элементы в конец,
- – извлекает элемент с конца,
- – извлекает элемент с начала,
- – добавляет элементы в начало.
- – начиная с индекса , удаляет элементов и вставляет .
- – создаёт новый массив, копируя в него элементы с позиции до (не включая ).
- – возвращает новый массив: копирует все члены текущего массива и добавляет к нему . Если какой-то из является массивом, тогда берутся его элементы.
-
Для поиска среди элементов:
- – ищет , начиная с позиции , и возвращает его индекс или , если ничего не найдено.
- – возвращает , если в массиве имеется элемент , в противном случае .
- – фильтрует элементы через функцию и отдаёт первое/все значения, при прохождении которых через функцию возвращается .
- похож на , но возвращает индекс вместо значения.
-
Для перебора элементов:
forEach(func) – вызывает func для каждого элемента. Ничего не возвращает.
-
Для преобразования массива:
- – создаёт новый массив из результатов вызова для каждого элемента.
- – сортирует массив «на месте», а потом возвращает его.
- – «на месте» меняет порядок следования элементов на противоположный и возвращает изменённый массив.
- – преобразует строку в массив и обратно.
- – вычисляет одно значение на основе всего массива, вызывая для каждого элемента и передавая промежуточный результат между вызовами.
-
Дополнительно:
Array.isArray(arr) проверяет, является ли arr массивом.
Обратите внимание, что методы , и изменяют исходный массив. Изученных нами методов достаточно в 99% случаев, но существуют и другие
Изученных нами методов достаточно в 99% случаев, но существуют и другие.
-
arr.some(fn)/arr.every(fn) проверяет массив.
Функция вызывается для каждого элемента массива аналогично . Если какие-либо/все результаты вызовов являются , то метод возвращает , иначе .
-
arr.fill(value, start, end) – заполняет массив повторяющимися , начиная с индекса до .
-
arr.copyWithin(target, start, end) – копирует свои элементы, начиная со и заканчивая , в собственную позицию (перезаписывает существующие).
Полный список есть в справочнике MDN.
На первый взгляд может показаться, что существует очень много разных методов, которые довольно сложно запомнить. Но это гораздо проще, чем кажется.
Внимательно изучите шпаргалку, представленную выше, а затем, чтобы попрактиковаться, решите задачи, предложенные в данной главе. Так вы получите необходимый опыт в правильном использовании методов массива.
Всякий раз, когда вам будет необходимо что-то сделать с массивом, а вы не знаете, как это сделать – приходите сюда, смотрите на таблицу и ищите правильный метод. Примеры помогут вам всё сделать правильно, и вскоре вы быстро запомните методы без особых усилий.






