27 распространённых вопросов по sql с собеседований и ответы на них
Содержание:
Предложение WHERE
После служебного слова указываются условия выбора строк, помещаемых в результирующую таблицу. Существуют различные типы условий выбора:
Типы условий выбора:
- Сравнение значений атрибутов со скалярными выражениями, другими атрибутами или результатами вычисления выражений.
- Проверка значения на принадлежность множеству.
- Проверка значения на принадлежность диапазону.
- Проверка строкового значения на соответствие шаблону.
- Проверка на наличие null-значения.
Сравнение
В языке SQL используются традиционные операции сравнения ,,,,,.
В качестве условия в предложении можно использовать сложные логические выражения, использующие атрибуты таблиц, константы, скобки, операции , , отрицание .
Пример 5.Определить номера деталей, поставляемых поставщиком с номером 2.
Пример 6.Получить информацию о поставщиках Иванов и Петров.
Строковые значения атрибутов заключаются в апострофы.
Проверка на принадлежность множеству
Операция проверяет, принадлежит ли значение атрибута заданному множеству.
Пример 7.Получить информацию о поставщиках ‘Иванов’ и ‘Петров’.
Пример 8.Получить информацию о деталях с номерами 1 и 2.
Проверка на принадлежность диапазону
Операция определяет минимальную и максимальную границу диапазона, в которое должно попадать значение атрибута. Обе границы считаются принадлежащими диапазону.
Пример 9.Определить номера деталей, с ценой от 10 до 20 рублей.
Пример 10.Вывести наименования поставщиков, начинающихся с букв от ‘К’ по ‘П’.
Сравнение символов
Буква ‘Р’ в условии запроса объясняется тем, что строки сравниваются посимвольно. Для каждого символа при этом определяется код. Для нашего случая справедливо условие: ‘П’<‘Петров’<‘Р’
Проверка строкового значения на соответствие шаблону
Операция используется для поиска подстрок. Значения столбца, указываемого перед служебным словом сравниваются с задаваемым после него шаблоном. Форматы шаблонов различаются в конкретных СУБД.
Для СУБД MS SQL Server:
- Символ заменяет любое количество любых символов.
- Символ заменяет один любой символ.
- ‑ вместо символа строки может быть подставлен один любой символ из множества возможных, указанных в ограничителях.
- ‑ вместо символа строки может быть подставлен любой из символов кроме символов из множества, указанного в ограничителях.
Множество символов в квадратных скобках можно указывать через запятую, либо в виде диапазона.
Пример 11.Вывести фамилии поставщиков, начинающихся с буквы ‘И’.
Пример 12.Вывести фамилии поставщиков, начинающихся с букв от ‘К’ по ‘П’.
Проверка на наличие null-значения
Операции и используются для сравнения значения атрибута со значением .
Пример 13.Определить наименования деталей, для которых не указана цена.
Пример 14.Определить номера поставщиков, для которых указано наименование.
Скажите нет грубой силе
Этот последний совет на самом деле означает, что вы не должны слишком сильно ограничивать запрос, потому что это может повлиять на его производительность. Это особенно верно для объединений и для предложения .
Когда вы объединяете две таблицы, может быть важно рассмотреть порядок объединения таблиц. Если вы заметили, что одна таблица значительно больше другой, вы можете переписать свой запрос так, чтобы самая большая таблица была помещена последней в объединении
Избыточные условия для объединений
Когда вы добавляете слишком много условий для объединений, вы, по сути, предписываете SQL выбрать определенный путь. Может быть, однако, что этот путь не всегда более эффективен.
Предложение было первоначально добавлено в SQL, потому что ключевое слово не могло использоваться с агрегатными функциями. обычно используется с предложением , чтобы ограничить группы возвращаемых строк только теми, которые соответствуют определенным условиям. Однако, если вы используете это предложение в своем запросе, индекс не используется, который, как вы уже знаете, что может привести к запросу, который будет не реально выполнить.
Если вы ищете альтернативу, подумайте об использовании предложения . Рассмотрим следующие запросы:
SELECT state, COUNT(*) FROM Drivers WHERE state IN ('GA', 'TX') GROUP BY state ORDER BY state
SELECT state, COUNT(*) FROM Drivers GROUP BY state HAVING state IN ('GA', 'TX') ORDER BY state
В первом запросе используется предложение , чтобы ограничить количество строк, которые нужно суммировать, тогда как второй запрос суммирует все строки в таблице, а затем использует для отбрасывания вычисленных сумм. В таких случаях альтернатива с предложением , очевидно, лучше, поскольку вы не тратите никаких ресурсов.
Вы видите, что здесь речь идет не о ограничении результатов запроса, а об ограничении промежуточного количества записей в запросе.
Обратите внимание, что разница между этими двумя предложениями заключается в том, что оператор вводит условие для отдельных строк, тогда как оператор вводит условие агрегирования или повторных выборов, в которых один результат, такой как , , , … был создан из нескольких строк. Как видите, оценка качества, запись и переписывание запросов –непростая задача, если учесть, что они должны быть максимально эффективными
Избегание анти-шаблонов и использование альтернативных вариантов в написании запросов также являются частью вашей заботы при написании очередей, которые можно запускать в базах данных в профессиональной среде
Как видите, оценка качества, запись и переписывание запросов –непростая задача, если учесть, что они должны быть максимально эффективными. Избегание анти-шаблонов и использование альтернативных вариантов в написании запросов также являются частью вашей заботы при написании очередей, которые можно запускать в базах данных в профессиональной среде.
Этот список был всего лишь небольшим обзором некоторых анти-шаблонов и советов, которые, надеюсь, помогут новичкам. Если вы хотите получить представление о том, что более старшие разработчики считают наиболее частыми антишаблонами, ознакомьтесь с этим обсуждением.
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
1) Выведем все имеющиеся у нас БД:
SELECT name, database_id, create_date FROM sys.databases;
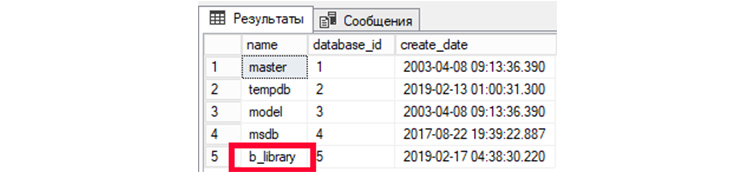
2) Выведем все таблицы в созданной нами ранее БД «b_library»:
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE=’BASE TABLE’
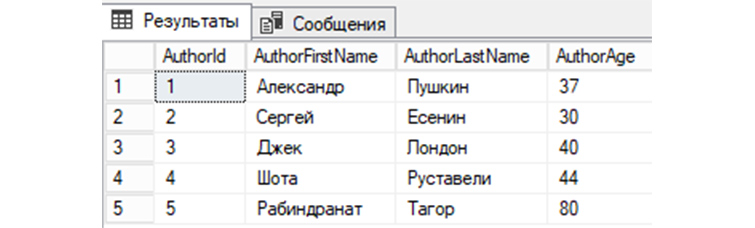
 3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
SELECT * FROM tAuthors;
 4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
SELECT count(*) FROM tAuthors;
 5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
SELECT * FROM tAuthors ORDER BY AuthorId OFFSET 3 ROWS FETCH NEXT 2 ROWS ONLY;
 6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
SELECT * FROM tAuthors ORDER BY AuthorFirstName;
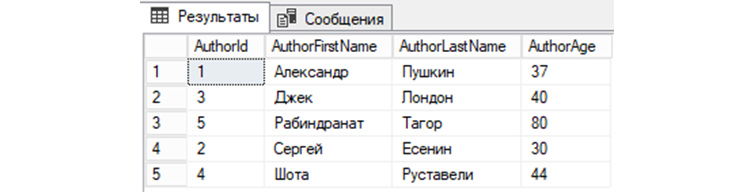 7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
SELECT * FROM tAuthors ORDER BY AuthorId DESC;
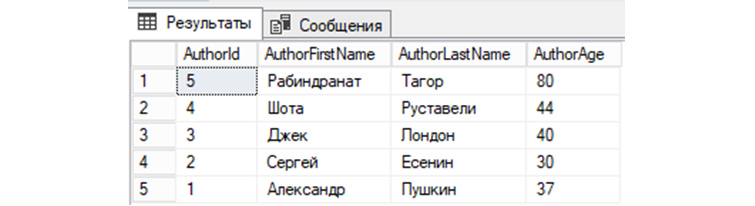 8) Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
8) Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
SELECT * FROM tAuthors WHERE AuthorFirstName=’Александр’;
 9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘се%’;
 10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘%ат’ ORDER BY AuthorId;
Видео курсы по схожей тематике:

SQL Базовый. Разбор ДЗ
Владимир Дымчук

MySQL Базовый
Андрей Бондаренко

Transact SQL
Станислав Зуйко
 11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
SELECT * FROM tAuthors WHERE AuthorId IN (2,4);
 12) Выберем в «tAuthors» такую запись AuthorAge, значение которой — наибольшее:
12) Выберем в «tAuthors» такую запись AuthorAge, значение которой — наибольшее:
SELECT max(AuthorAge) FROM tAuthors;
 13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
SELECT AuthorFirstName, AuthorLastName FROM tAuthors;
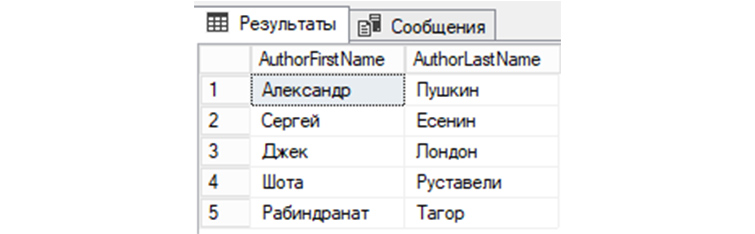 14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
SELECT AuthorId, AuthorFirstName, AuthorLastName FROM tAuthors WHERE AuthorId!=’3′;
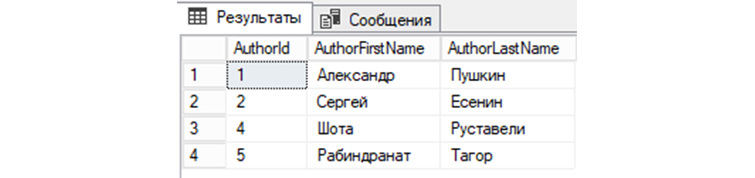
INSERT
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД. Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.
INSERT INTO tAuthors VALUES (‘Уильям’, ‘Шекспир’, ’51’);
Проверим:
SELECT * FROM tAuthors;
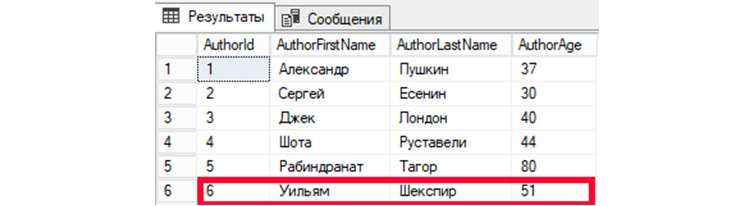
UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (AuthorId = 6). Значения изменим для полей имени, фамилии и возраста автора.
UPDATE tAuthors SET AuthorFirstName = ‘Лев’, AuthorLastName=’Толстой’, AuthorAge = ’82’ WHERE AuthorId = ‘6’;
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
SELECT * FROM tAuthors;
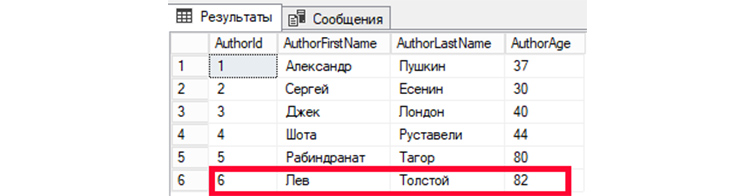
Мы видим изменения информации в записи автора под номером 6.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где AuthorId = 5:
DELETE FROM tAuthors WHERE AuthorId = ‘5’;
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
SELECT * FROM tAuthors;
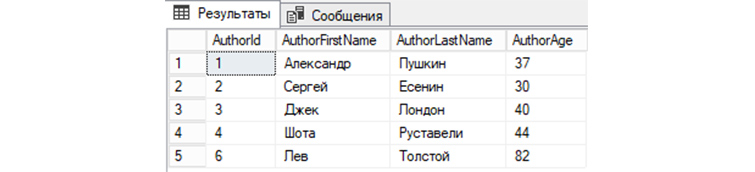
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors целиком, выполнив простой SQL запрос:
DROP TABLE tAuthors;
Далее рассмотрим сложные запросы SQL.
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
Создание таблицы
Синтаксис:
> CREATE TABLE <table> (<field1> <options1>, <field2> <options2>) <table options>
Пример:
> CREATE TABLE IF NOT EXISTS `users_rights` (
`id` int(10) unsigned NOT NULL,
`user_id` int(10) unsigned NOT NULL,
`rights` int(10) unsigned NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf-8;
* где table — имя таблицы (в примере users_rights); field1, field2 — имя полей (в примере создается 3 поля — id, user_id, rights); options1, options2 — параметры поля (в примере int(10) unsigned NOT NULL); table options — общие параметры таблицы (в примере ENGINE=InnoDB DEFAULT CHARSET=utf-8).
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Подключение SQL к C#
C#, как и SQL-запросы внедрялись в программирование корпорацией Microsoft. Поэтому провести их интеграцию не составит никакого труда. После этого удастся писать универсальные приложения, которые будут работать на языке запросов информационных баз.
Для реализации поставленной задачи в основном используются специальные команды, а также дополнительный контент – ADO.Net или SQL Server. Создавать «хранилище сведений» требуется через второй «элемент». Отыскать приложение предварительно предлагается на сайте Microsoft.
После того, как произошло создание таблицы, требуется определить строчку подключения, которая предоставляет материалы о БД и сервере:
Далее пользователю предстоит для выполнения команды задействовать методы SQLCommand:
- ExecuteNonQuery. Обычное выполнение выражения, а затем возврат измененных записей. Подойдет для Insert, Delete, Update (Select сюда не включен).
- ExecuteReader. Отвечает за выполнение выражения и возврат строчки из таблички. Годится для Select.
- ExecuteScalar. Осуществляется обработка выражения с последующим возвратом одного скаляра. Пример – числа. Используется с Select в паре со встроенными функциями-SQL (Min. Max, Count, Sum).
На самом деле все не так трудно, как кажется. В видео по данной ссылке хорошо показано, каков порядок выполнения SQL запросов. Этот вариант актуален только для C#. В Google полно подобных туториалов. Если одно видео не понятно новичку, он всегда сможет отыскать что-то более ясное для себя.
Основные моменты при изучении Sql
Как уже отмечалось выше, запросы применяются для обработки и ввода новой информации в БД, состоящую из таблиц. Каждая ее строка — это отдельная запись. Итак, создадим БД. Для этого напишите команду:
Create database ‘bazaname’
В кавычках пишем имя БД на латинице. Старайтесь придумать для нее понятное имя. Не создавайте базу типа «111», «www» и тому подобное.
После создания БД устанавливаем кодировку windows-1251:
SET NAMES ‘utf-8’
Это нужно чтобы контент на сайте правильно отображаться.
Теперь создаем таблицу:
CREATE TABLE ‘bazaname’ . ‘table’ (
id INT(8) NOT NULL AUTO_INCREMENT PRIMARY KEY,
log VARCHAR(10),
pass VARCHAR(10),
date DATE
);
Во второй строке мы прописали три атрибута. Посмотрим, что они означают:
- Атрибут NOT NULL означает, что ячейка не будет пустой (поле обязательное для заполнения);
- Значение AUTO_INCREMENT — автозаполнение;
- PRIMARY KEY — первичный ключ.
Пример
Теперь, зная синткасис команд INSERT и SELECT, можем разобраться как создать из исходного набора данных словари и загрузить данные в БД с учетом внешних ключей
Допустим есть список агентов (данные полученные от заказчика в виде CSV-файла), у которых есть поля название, тип и т.д. (далее по тексту я её называю таблица импорта)

В структуре БД поле «тип агента» создано как внешний ключ на таблицу типов
Заполнение словарей
Для добавления «типов агентов» в таблицу AgentType мы будем использовать альтернативный синтаксис
-
Пишем инструкцию SELECT, которая выбирает уникальные записи из таблицы импорта:
SELECT DISTINCT Тип_агента FROM agents_import- Ключевое слово DISTINCT относится только к топу полю, перед которым написано. В нашем случае выбирает уникальные названия типов агентов.
- Откуда брать поле Image в предметной области не написано и в исходных данных его нет. Но т.к. в целевой таблице это поле не обязательное, то можно его пропустить
Этот запрос можно выполнить отдельно, чтобы проверить что получится
-
После отладки запроса SELECT перед ним допишем запрос INSERT:
INSERT INTO AgentType (Title) SELECT DISTINCT Тип_агента FROM agents_import- Поле ID можно пропустить, оно автоинкрементное и создастся само (по крайней мере в MsSQL)
- Количество вставляемых полей (Title) должно быть равным количеству выбираемых полей (Тип_агента)
Если в таблице есть обязательные поля, а нем неоткуда взять для них данные, то мы можем в SELECT вставить фиксированные значения (в примере пустая строка):
Заполнение основной таблицы
Тоже сначала пишем SELECT запрос, чтобы проверить те ли данные получаются
напоминаю, что порядок и количество выбираемых и вставляемых полей должны быть одинаковыми
в поле AgentTypeID мы должны вставить ID соответсвующей записи из таблицы AgentType, поэтому выборка у нас из двух таблиц и чтобы не писать перед каждым полем полные названия таблиц мы присваиваем им алиасы
SELECT
asi.Наименование_агента,
att.ID,
asi.Юридический_адрес,
asi.ИНН,
asi.КПП,
asi.Директор,
asi.Телефон_агента,
asi.Электронная_почта_агента,
asi.Логотип_агента,
asi.Приоритет
FROM
agents_import asi,
AgentType att
WHERE
asi.Тип_агента=att.Title
Т.е. мы выбираем перечисленные поля из таблицы agents_import и добавляем к ним ID агента у которого совпадает название.
При выборке из нескольких таблиц исходные данные перемножаются. Т.е. если мы не заполним перед этой выборкой словарь, то .
Если же мы не укажем условие WHERE, то выберутся, к примеру, записей (каждый агент будет в каждой категории)
Поэтому важно, чтобы условие WHERE выбирало уникальные значения.
Естественно, количество внешних ключей в таблице может быть больше одного, в таком случае в секции FROM перечисляем все используемые словари и в секции WHERE перечисляем условия для всех таблиц объединив их логическим выражением AND
где алиасы b, c, d — словарные таблицы, а алиас «а» — таблица импорта
Написав и проверив работу выборки (она должна возвращать чтолько же записей, сколько в таблице импорта) дописываем команду вставки данных:
INSERT INTO Agent (Title, AgentTypeID, Address, INN, KPP, DirectorName, Phone, Email, Logo, Priority)
SELECT
asi.Наименование_агента,
att.ID,
asi.Юридический_адрес,
asi.ИНН,
asi.КПП,
asi.Директор,
asi.Телефон_агента,
asi.Электронная_почта_агента,
asi.Логотип_агента,
asi.Приоритет
FROM
agents_import asi,
AgentType att
WHERE
asi.Тип_агента=att.Title
Зачем мне изучать SQL, если я занимаюсь данными?
SQL весьма далек от забвения – напротив, это один из самых востребованных навыков, который вы можете найти в описаниях вакансий в области обработки больших данных, независимо от того, хотите ли вы устроиться на должность аналитика данных, инженера по данным, научного сотрудника в области данных или в качестве еще кого-либо. Этот факт подтверждается результатами исследования рынка труда, проведенным O’Reilly в 2016 году: 70% респондентов, участвовавших в опросе, подтвердили, что в своей профессиональной деятельности они используют SQL. Более того, в обзоре результатов этого исследования язык SQL занимает более высокую позицию, по сравнению с другими языками программирования, такими как R (57%) и Python (54%).
Теперь вы понимаете в чем тут дело: SQL является обязательным навыком, если вы хотите получить работу в сфере обработки больших данных.
Неплохо для языка, который был разработан еще в начале 1970-х годов прошлого века, не правда ли?
Но почему так часто используется именно этот язык? И почему он до сих пор не мертв, как многие другие языки того же поколения?
Для объяснения этого факта можно найти несколько причин: во-первых, компании в основном хранят данные в реляционных системах управления базами данных (RDBMS) или в системах управления реляционными потоками данных (RDSMS), и SQL требуется для доступа к таким хранимым данным. SQL – это универсальный язык данных: он дает вам возможность взаимодействовать практически с любой базой данных или даже создавать свои локальные базы данных!
Только имейте в виду, что существует немало реализаций SQL, которые несовместимы между собой и не обязательно соответствуют стандартам. Знание стандартного SQL, таким образом, является обязательным для каждого, желающего найти свой путь в это наукоемкой отрасли.
Кроме того, можно с уверенностью сказать, что SQL также включается в новые технологии, такие как Hive, SQL-подобный язык запросов, ориентированный на запросы и управление большими наборами данных, или Spark SQL, которые вы можете использовать для выполнения SQL запросов. Но еще раз напоминаем, SQL, который вы найдете в этих технологиях, будет отличаться от стандартного, который вы, возможно, уже знаете, но разобраться в особенностях конкретной реализации, зная стандартный SQL, вам будет значительно проще.
Если хотите, можем привести такую аналогию с линейной алгеброй: сосредоточив все усилия только на этой одной области математики, вы сможете использовать полученные знания и как хорошую основу для овладения машинным обучением!
Короче говоря, вот причины, по которым вам следует изучить язык структурированных запросов:
- Он довольно прост в изучении, даже для новичков. Рост знаний и навыков происходит довольно быстро, и вы в кратчайшие сроки научитесь писать запросы.
- Изучение SQL подчиняется принципу «однажды изученное может применяться повсюду», поэтому это отличное вложение вашего времени и сил!
- Это отличное дополнение к языкам программирования. В некоторых случаях писать запрос даже предпочтительнее, чем писать код, потому что он более эффективен!
- …
И чего же ты все еще ждешь?
Подзапросы SQL с инструкцией DELETE
Ниже приводится синтаксис и пример использования SQL подзапросов с инструкцией DELETE.
Синтаксис:
DELETE FROM TABLE_NAME (SELECT COLUMN_NAME FROM TABLE_NAME)
Если нужно удалить заказы из таблицы «neworder», для которых advance_amount меньше максимального значения advance_amount из таблицы «orders», можно использовать следующий код SQL:
Пример таблицы: neworder
ORD_NUM ORD_AMOUNT ADVANCE_AMOUNT ORD_DATE CUST_CODE AGENT_CODE ORD_DESCRIPTION ---------- ---------- -------------- --------- --------------- --------------- ----------------- 200114 3500 2000 15-AUG-08 C00002 A008 200122 2500 400 16-SEP-08 C00003 A004 200118 500 100 20-JUL-08 C00023 A006 200119 4000 700 16-SEP-08 C00007 A010 200121 1500 600 23-SEP-08 C00008 A004 200130 2500 400 30-JUL-08 C00025 A011 200134 4200 1800 25-SEP-08 C00004 A005 200108 4000 600 15-FEB-08 C00008 A004 200103 1500 700 15-MAY-08 C00021 A005 200105 2500 500 18-JUL-08 C00025 A011 200109 3500 800 30-JUL-08 C00011 A010 200101 3000 1000 15-JUL-08 C00001 A008 200111 1000 300 10-JUL-08 C00020 A008 200104 1500 500 13-MAR-08 C00006 A004 200106 2500 700 20-APR-08 C00005 A002 200125 2000 600 10-OCT-08 C00018 A005 200117 800 200 20-OCT-08 C00014 A001 200123 500 100 16-SEP-08 C00022 A002 200120 500 100 20-JUL-08 C00009 A002 200116 500 100 13-JUL-08 C00010 A009 200124 500 100 20-JUN-08 C00017 A007 200126 500 100 24-JUN-08 C00022 A002 200129 2500 500 20-JUL-08 C00024 A006 200127 2500 400 20-JUL-08 C00015 A003 200128 3500 1500 20-JUL-08 C00009 A002 200135 2000 800 16-SEP-08 C00007 A010 200131 900 150 26-AUG-08 C00012 A012 200133 1200 400 29-JUN-08 C00009 A002 200100 1000 600 08-JAN-08 C00015 A003 200110 3000 500 15-APR-08 C00019 A010 200107 4500 900 30-AUG-08 C00007 A010 200112 2000 400 30-MAY-08 C00016 A007 200113 4000 600 10-JUN-08 C00022 A002 200102 2000 300 25-MAY-08 C00012 A012
Код SQL:
DELETE FROM neworder WHERE advance_amount< (SELECT MAX(advance_amount) FROM orders);
Результат:
Пожалуйста, оставляйте ваши мнения по текущей теме статьи. Мы очень благодарим вас за ваши комментарии, лайки, подписки, дизлайки, отклики!
Вадим Дворниковавтор-переводчик статьи «SQL Subqueries»






