Hackware.ru
Содержание:
- Which Sites Are Cataloged?
- Как отправить страницу на Wayback Machine
- Больше информации о Wayback Machine
- Возможности использования веб-архивов
- How to Use the Wayback Machine
- Что такое Wayback Machine и Архивы Интернета
- Как добавить современную версию сайта в веб-архив Wayback Machineи выполнить другие действия
- Инструкция по ручному удалению рекламного вируса WAYBACK MACHINE
- Method 2: using FTP
- Качаем сайт с web-arhive.ru
- web.archive.org
- Introduction
- Installing the Latest Build
- Как пользоваться веб архивом
- Archive-It
- Reasons for using the Wayback Downloader
- Как использовать Wayback Machine
- Installation Method 1: The Easy Method
- Features
Which Sites Are Cataloged?
Many popular websites are automatically archived by the Wayback Machine. However, you can use the Wayback Machine to manually archive virtually any page. Websites are often abandoned or changed completely, so the Wayback machine acts as a way to preserve the culture of the Internet by keeping a digital “hard copy” of a website. Be aware that text and images are left intact; however, some outbound links and embedded items (e.g. videos) are not.
It is important to note that The Wayback Machine only scans and archives public sites. This means that password protected sites or ones located on private servers cannot be archived. In addition, if a website prohibits search engines from including it in search results, Wayback Machine will not be able to archive it.
Как отправить страницу на Wayback Machine
Вы можете добавить страницу в Wayback Machine в любое время. Чтобы заархивировать конкретную страницу в том виде, в каком она есть на данный момент, будь то законная ссылка или просто личная ссылка, перейдите в область « Сохранить страницу сейчас» на сайте и вставьте ссылку в текстовое поле.

На этой странице есть несколько других опций, которые вы можете включить, если хотите:
- Сохранение ссылок : Экономьте время, и Wayback Machine сохраняет даже ссылки, на которые указывает страница.
- Сохранить страницы ошибок (HTTP Status = 4xx, 5xx) : Сохранить страницы, даже если они возвращают ошибку кода состояния HTTP .
- Сохранить снимок экрана : сохранить версию изображения страницы в дополнение к обычному снимку с переходом по клику.
- Сохраните также в моем веб-архиве : если вы вошли в систему, вы увидите эту опцию, которая хранит ссылку на архив в вашей учетной записи для быстрого доступа позже.
Еще один способ использовать Wayback Machine для архивирования веб-страницы — использовать букмарклет. Используйте приведенный ниже код JavaScript в качестве местоположения новой закладки / избранного в вашем браузере и выберите его на любой веб-странице, чтобы мгновенно отправить его на Wayback Machine для архивирования.
Другой вариант отправки страниц на Wayback Machine — расширение Chrome Wayback Machine ; есть и Firefox . Это расширение на самом деле делает гораздо больше, чем просто сохраняет страницы на своем веб-сайте — вы можете использовать его для просмотра страницы на Wayback Machine и автоматической загрузки заархивированной страницы, если открытая страница не работает.

Больше информации о Wayback Machine
Страницы, отображаемые на Wayback Machine, отражают только те, которые были заархивированы службой, а не частоту обновления страницы. Другими словами, в то время как одна страница, которую вы посетили, могла обновляться один раз в день в течение целого месяца, Wayback Machine могла заархивировать ее только несколько раз или не делать вообще.
Не каждая существующая веб-страница архивируется Wayback Machine. Они не добавляют веб-сайты чата или электронной почты в свой архив и не могут включать веб-сайты, которые явно блокируют Wayback Machine, веб-сайты, которые скрыты за паролями, и другие частные сайты, которые не являются общедоступными.
Wayback Machine будет захватывать URL так часто, как каждые пять минут. Если вы попытаетесь заархивировать идентичную страницу раньше, вы получите ошибку.
Если у вас есть дополнительные вопросы о Wayback Machine, вы, скорее всего, сможете найти ответы на странице часто задаваемых вопросов Wayback Machine в Интернет-архиве .
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
How to Use the Wayback Machine
There are two methods you can use to start archiving websites. Fortunately, both of them are super-easy and don’t require any special know-how. Start by placing your cursor in front of the URL in your browser’s address bar. Type and hit Enter. A dialog box should appear on your screen informing you that the Wayback Machine is saving the page.
The second way to archive a webpage is to use the Wayback Machine archive website. First, navigate to a webpage you want to save and copy the URL. With that done, head to the Wayback Machine archive website. On the right side of this page you will see a header that reads “Save Page Now.” Paste the URL of the webpage you want to save into the text box and click the “Save Page” button.
Regardless of which method you use, the result is the same. Be aware that saving the page can take a while, so be patient and let it do its thing.
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Как добавить современную версию сайта в веб-архив Wayback Machineи выполнить другие действия
Онлайн-платформа по веб-архивированию сайтов предоставляет множество возможностей разработчикам и владельцам ресурсов (Табл. 2).
Табл. 2. Как работать с веб-архивом
| Возможности | Особенности выполнения |
| Сохранение нужной версии сайта на платформе интернет-архива | Нужно самостоятельно инициировать сохранение. В разделе платформы «Save Page Now» нужно забить домен онлайн-ресурса и нажать «Save page». Такую процедуру рекомендуется повторять каждый раз, когда в контент были внесены исправления или дополнения |
| Запрет на добавление интернет-ресурса в память веб-архива | Для запрета добавления нужно прописать это в файле robots.txt. В панелях хостеров есть корневой каталог, в котором предусмотрена возможность редактирования файлов. При введении кода User-agent: ia_archiverDisallow: /User-agent: Disallow: / файл будет скрыт от копирования. При введении такого кода из веб-архива удаляется и текущая версия сайта и не осуществляется системное копирование (до тех пор, пока в файле robots.txt есть такие настройки или пока не закончится срок регистрации домена) |
| Восстановление веб-сайта из интернет-архива | Если сайт был поврежден вирусами или есть другие технические проблемы, из-за которых контент был нарушен, можно восстановить файлы из онлайн-хранилища. Для этого применяются специальные сервисы. Есть платные и бесплатные варианты, которые выбираются с учетом количества страниц для восстановления |
Инструкция по ручному удалению рекламного вируса WAYBACK MACHINE
Для того, чтобы самостоятельно избавиться от рекламы WAYBACK MACHINE, вам необходимо последовательно выполнить все шаги, которые я привожу ниже:
- Поискать «WAYBACK MACHINE» в списке установленных программ и удалить ее.
Открыть Диспетчер задач и закрыть программы, у которых в описании или имени есть слова «WAYBACK MACHINE». Заметьте, из какой папки происходит запуск этой программы. Удалите эти папки.
Запретить вредные службы с помощью консоли services.msc.
Удалить “Назначенные задания”, относящиеся к WAYBACK MACHINE, с помощью консоли taskschd.msc.
С помощью редактора реестра regedit.exe поискать ключи с названием или содержащим «WAYBACK MACHINE» в реестре.
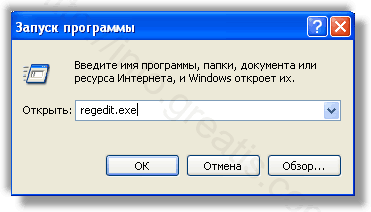
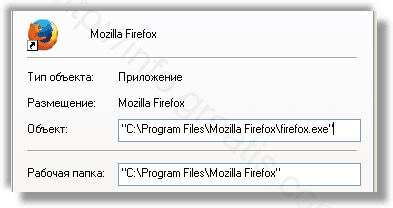
Проверить ярлыки для запуска браузеров на предмет наличия в конце командной строки дополнительных адресов Web сайтов и убедиться, что они указывают на подлинный браузер.
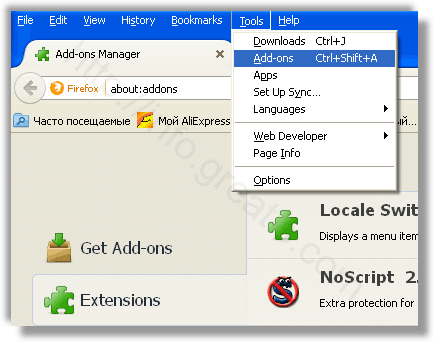
Проверить плагины всех установленных браузеров Internet Explorer, Chrome, Firefox и т.д.
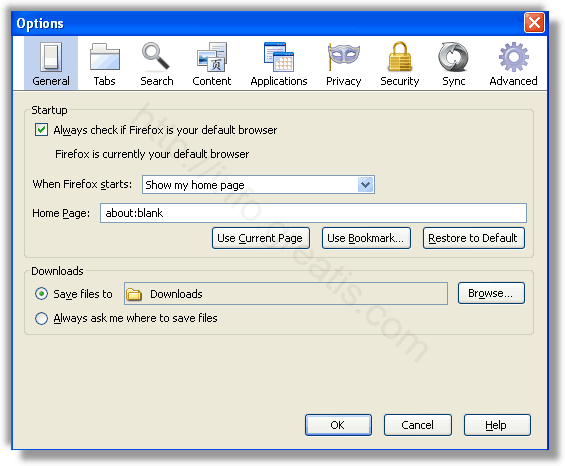
Проверить настройки поиска, домашней страницы. При необходимости сбросить настройки в начальное положение.
Очистить корзину, временные файлы, кэш браузеров.
Method 2: using FTP
This Tutorial explains how you can recover a website from the Waybackmachine. It also explains exactly how you can upload the files with Cpanel and FTP.
- 1. Download the .zip file with all the HTML files. Extract the files (unzip) to a folder of your choice.
- 2. You need to transfer the files to the server using FTP software. If you don’t have an FTP client already, then we recommend FileZilla: https://filezilla-project.org/
-
3. If you don’t already have an FTP account at your hosting provider, then create one. If your host uses cPanel, then find the icon that says «FTP Accounts» (most hosting providers use cPanel: Hostgator, Godaddy, BlueHost : all of them use cPanel)
cPanel example:It’s usually easier to create an FTP account when adding a domain to your hosting:
- 4. Find the IP address of your server. In GoDaddy you can find your IP address on the hosting dashboard:
-
5. We use FileZilla for Windows in this guide, but you can also download it for Apple computers.
You should now have an FTP account and know your IP address. Open an FTP client. We use FileZilla in this guide.
— Fill in your username and password.
— The username should be
— Host should be the IP address of your server, that will host the Wayback files.
— Port can be blank.
— Press Quickconnect to connect. - 6. Now select all the files and move them to the remote site:
- 7. Your site should work now.
Качаем сайт с web-arhive.ru
Это самый геморройный вариант ибо у данного сервиса нет возможности скачать сайт как у описанного выше. Соответственно пользоваться этим вариантом есть смысл пользоваться только в случае если нужно скачать сайт, которого нет на web.archive.org. Но я сомневаюсь что такое возможно. Этим вариантом я пользовался по причине того, что не знал других вариантов,а поискать поленился.
В итоге я написал скрипт, который позволяет скачать архив сайта с web-arhive.ru. Но велика вероятность того, что это будет сопровождаться ошибками, поскольку скрипт сыроват и был заточен под скачивание определенного сайта. Но на всякий случай я выложу этот скрипт.
Вот ссылка: https://yadi.sk/d/zoMRxwPoSXh0Jw
Пользоваться им довольно просто. Для запуска скачивания необходимо запустить этот скрипт все в той же командной строке, где в качестве параметра вставить ссылку на копию сайта. Должно получиться что-то типа такого:
php get_archive.php «http://web-arhive.ru/view2?time=20160320163021&url=http%3A%2F%2Fremontistroitelstvo.ru%2F»
Заходим на сайт web-arhive.ru, в строке указываем домен и жмем кнопку «Найти». Ниже должны появится года и месяцы в которых есть копии.
Обратите внимание на то, что слева и справа от годов и месяцев есть стрелки, кликая которые можно листать колонки с годами и месяцами
Остается найти дату с нужной копией, скопировать ссылку из адресной строки и отдать её скрипту. Не забывает помещать ссылку в кавычки во избежание ошибок из-за наличия спецсимволов.
Мало того, что само скачивание сопровождается ошибками, более того, в выбранной копии сайта может не быть каких-то страниц и придется шерстить все копии на предмет наличия той или иной страницы.
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».
Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:
В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.
При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время:
Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:
Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
Introduction
wayback is an open source java implementation of the
The Internet Archive
Wayback Machine.
The current production version of the Wayback Machine is implemented in
perl, and lacks in maintainability and extensibility. Also, the code is
not open source. Primary motivation for the new version is to address
these three issues, enabling public distribution of the application, and
easy experimentation with new features and access technologies.
The current Java version of the Wayback Machine supports three access,
or Replay modes of operation: «Archival Url» mode «Proxy» mode, and
«Domain Prefix» mode.
Archival URL mode provides a user experience very close to the current
production Wayback Machine. All query and replay access requests can be
expressed as URLs. In Archival Url replay mode, archived content is
modified as it is returned to users, attempting to make links and
embedded content refer back to the Wayback Machine by rewriting them as
Archival URLs.
Proxy URL mode allows replaying of archived documents within a client
browser by configuring the browser to proxy all HTTP requests through
the Wayback Machine. This has the strong advantage that no Javascript
or server side page markup is required to coerce the client browser to
request additional URLs and embedded content from the Wayback Machine
— content just works as-is. When used with the Firefox plugin
extension, available
here
, client browsers can navigate between versions of the current
document, and the Wayback Machine server will attempt to display images
from the same time period as pages being viewed. The Proxy URL mode
requires special configuration of the client web browser to access the
Wayback Service. This browser configuration is not complex, but it
means that content cannot be accessed as a global URL.
DomainPrefix mode is similar to ArchivalUrl mode, but uses a wildcard
DNS scheme to rewrite URLs, allowing all URL substitution to occur on
the server. This mode is considered experimental.
See the Administrator Manual
to learn more about access modes.
The current Java version can operate in several deployment modes,
ranging from a stand alone application on a single host holding all
archived documents and indexes, up to a highly distributed system where
indexes and archived content is spread across hundreds of machines.
Installing the Latest Build
First tap on the Code button, Download ZIP, unzip the file in a location where you can find on your computer, then follow the steps below for your browser.
Chrome
- Open Chrome and navigate to in your browser. You can also access this page by clicking on the 3 vertical dots menu on the top-right, hovering over More Tools, then selecting Extensions.
- Turn on the switch next to Developer mode.
- Click the Load unpacked button and select the directory that contains this code.
- Click on the Extensions puzzle-like icon in the toolbar.
- Now click on the Pin icon next to Wayback Machine to pin it.
- Click on the newly added icon.
- Read the terms, then Accept and Enable. Click on the icon again to use the extension.
Firefox
- Open Firefox and navigate to in the browser. You can also access this page by clicking on the hamburger menu on the top-right, select Add-ons, then the Gear Tools button on the top-right, then Debug Add-ons.
- Click This Firefox on the left.
- Click Load Temporary Add-on…
- Open the directory and select any file.
- Click on the newly added icon in the toolbar.
- Read the terms, then Accept and Enable. Click on the icon again to use the extension.
Edge
- Open Edge and navigate to in your browser. You can also access this page by clicking on the 3 horizontal dots menu on the top-right, then clicking Extensions.
- Turn on the switch next to Developer mode.
- Click the Load unpacked button and select the directory that contains this code.
- Click on the newly added icon in the toolbar.
- Read the terms, then Accept and Enable. Click on the icon again to use the extension.
Safari 14+
This will require Xcode to compile from source.
- Open Safari.
- If Develop menu is hidden, go to Preferences > Advanced > check «Show Develop menu in menu bar».
- Then Develop menu > Allow Unsigned Extensions (enter password).
- Open the project file in Xcode. Click Play to run.
- Follow directions in splash window:
- Safari menu > Preferences > Extensions tab.
- Check to activate Wayback Machine.
- Select «Always Allow on Every Website…» button and confirm.
- Click on the newly added icon in the toolbar.
- Read the terms, then Accept and Enable. Click on the icon again to use the extension.
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».
Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).
Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.
Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Archive-It
Do you or your organization have a website that needs to be indexed and archived frequently? If so, manually archiving each individual web page using the methods above can be incredibly tedious and costly. Fortunately, the Internet Archive provides a service called Archive-It that can automate the archiving process for you.
This service is not free; however, it can be ideal for those who want to back up their content with a “set it and forget it” mentality. Just stipulate which pages you would like to save and how often. This paid subscription is perfect for those who wish to save their web content on a regular basis.
Do you use the Wayback Machine? If so, do you visit it purely for fun or do you find it a useful tool? Are there other ways to back up content on the Web? Let us know in the comments!
Reasons for using the Wayback Downloader
What possible reasons can you have to download sites from the Wayback Machine?
- Missed hosting payments. Let’s say you’re super responsible webmaster. You always update and keep fresh content. You do security updates. You’re on top of things. But one day, you visit your website and all your content is gone! It’s in this moment that you remember that you forgot to change that credit card that was linked to your hosting account. Now all your content is gone! Dashed away by one false move..or is it? Enter our web Archive download bot. With a few simple clicks, you can be on your way to restoring a whole website — exactly like it used to be.
- Nostalgia. Maybe you played a computer game as a teenager or you used to frequently visit some hobby website. Many of these websites change or go offline, but with an archive.org download order, you can recover all your nostalgic memories.Simply go to our wayback machine download site and create your own web.archive.org download. This includes your whole website, up to 10 levels deep, which means all pages that are 10 clicks away from the front page.
- Your site was hacked. What if a more sinister plot involving a hacker compromising the security of your site arises? He’s hijacked your site, and now all your content has been deleted and replaced with ads for his own benefit. Not to worry! We have you covered with a nice Wayback machine download of your website, as it was before disaster struck.
- Legal evidence. Should you ever find yourself embroiled in a legal battle over whatever the issue may be, The Wayback Downloader can help here too. Make a copy of the web archive data for use as evidence in lawsuits. For example, patent law and evidence of prior art. The Wayback Machine accepts removal requests, so it’s a good idea to have your own copy in case the website disappears from the web archive.
- Take content from bankrupt competitor. What if one of your biggest competitors has gone out of business, and with their exit from the business they also took down their website? Remember the URL? Voila! You’ve got yourself a ton of useable information to populate your new site with one less competitor to worry about. Basically, this can be for any site in your industry that was taken offline.
- For recovering expired content. Sometimes you have good expired content — perhaps you found it with our service or with software like the Expired Article Hunter. Let’s say you have a good PBN domain with high metrics, and you have another domain with good expired content. Now you can merge the two domains and rebuilding the expired content on the domain with high metrics. It’s one of the quickest and best methods to build a PBN
- Use it as an alternative to httrack. Httrack is software to scrape live websites, but it doesn’t do a very good job at scraping the internet archive. We rebuild websites as they once were, while httrack simply copies a complete site, including all the headers and archive URLs.
Как использовать Wayback Machine
На Wayback Machine есть несколько различных функций, но наиболее выдающимся является инструмент поиска, позволяющий определить, как веб-сайт выглядел ранее.
СМОТРЕТЬ АРХИВ ВЕБ-СТРАНИЦЫ
-
Посетите Wayback Machine на веб-сайте интернет-архива.
-
Выполните поиск Wayback Machine, вставив или введя URL-адрес в текстовое поле.
-
Используйте график в верхней части календаря, чтобы выбрать год.
-
Наведите указатель мыши на любой из кругов в календаре на этот год, а затем выберите конкретное время, чтобы просмотреть снимок, сделанный в то время.
Только дни, выделенные кружком, содержат архив. Большие круги показывают, что в этот день было сделано больше снимков, чем дни, представленные меньшим кругом.
-
Просмотрите архивную веб-страницу, как если бы она была сегодня. Вы можете нормально переходить по ссылкам (если есть архивы для этих страниц), загружать файлы и т. Д.
-
Чтобы перейти к другому дню для того же URL-адреса, используйте временную шкалу вверху.
ПОСМОТРЕТЬ ИЗМЕНЕНИЯ МЕЖДУ ДВУМИ ДАТАМИ
Область « Изменения» веб-сайта, которую вы видите после использования инструмента поиска Wayback Machine, позволяет сравнивать две даты одного и того же веб-сайта, чтобы наглядно увидеть, что изменилось между датами.

СМОТРИТЕ РЕЗЮМЕ САЙТА
Wayback Machine включает в себя раздел « Сводка » для URL, который вы ищете, который детализирует различные документы на странице между двумя годами. Инструмент дает количество файлов HTML , изображений и других типов файлов.

Installation Method 1: The Easy Method
- 1. Register the domain with your hosting company. If you have registered the domain elsewhere, then create an add-on domain in the cPanel of your hosting company. Here is a tutorial from GoDaddy, that explains how to create an add-on domain.
- 2. Login to cPanel and go to «File Manager», as shown in the picture below:
- 3. Browse to the root folder of your domain. Normally this is /public_html/example.com, as shown below. For this tutorial, we used the domain buy-searchengine.com. Then click on «Upload»:
- 4. Then upload the ZIP file, as shown in the picture below. This assumes that you have already downloaded the ZIP file from waybackmachinedownloader.com.
- 5. Extract the ZIP file:
- 6. That’s it! If you purchased the domain and the hosting from different companies, then you still have to change the name servers at your domain registrar, and change them with the name servers from your hosting company.
- 7. If you want to edit the front page, then go to the File Manager and edit the index.html file, using a text editor. You might find it easier to copy part of that file and edit it with an online HTML editor.
WordPress installation instructions
If you also ordered the WordPress conversion, then wait until one of our developers sends you a ZIP file with WordPress files. This might take up to 48 hours after the scraping has finished.
It might sound strange, but you can not use a «Managed WordPress» hosting package. It doesn’t provide enough rights to edit the database. However, any cheap shared hosting package works, as long as it uses Apache. You can get this from providers such as Godaddy or Hostgator. We recommend Namecheap because it’s good enough and costs only $35/year.
- 8. Upload and extract this ZIP file as described above in step 2-6, in the same way as you would do with a zip file with HTML files. In the ZIP file there is also a folder called «database». If you want to save some time, you can remove this folder from the ZIP file, because you do not need to upload it. You will need the folder later though.
- 9. Go to your cPanel and open «MySQL Databases». Create a new database. You can name it anything, but in our example we use the name of our domain. You will need this name later, so pick something easy.
- 10. Create a new user and password. The name can be anything, but you’ll need it later.
- 11. Add this user to the database. Give your new user access to all privileges.
- 12. On your own computer, unzip the folder called «database». For example, unzip this to your desktop.
- 13. Go to your cPanel and open «phpMyAdmin».
- 14. First select your database on the left panel, by clicking on it. Then click «import» and import the database. This is the .sql file in the folder called «database».
- 15. Go to File Manager and find the file called «wp-config.php». Open this file in a text editor.
-
16. In wp-config.php, edit the database name, database user name and database password. Use the values that you created in step 9 and 10.
With some hosts you also have to change the hostname, but with 95%+ of hosting companies, you can leave this as «localhost». For example with iPage it is «UsernameOfYourAccount.ipagemysql.com» - 17. That’s it! Your WordPress website should now work.
Features
- Save Page Now — Instantly save the page you are currently viewing in the Wayback Machine. Turn on Auto Save Page in settings to save pages that have not previously been saved. Must be logged in to use.
- Oldest, Newest & Overview — View the first version of a page or the most recently saved in the Wayback Machine. Or view a calendar overview of all archived pages.
- Replace 404s, etc… — When an error occurs, automatically check if an archived copy is available. Checks against 4xx & 5xx HTTP error codes.
- Wayback Machine Count — Display count of snapshots of the current page stored in the Wayback Machine.
- Relevant Resources — View archived digitized books while visiting Amazon Books, research papers and books while visiting Wikipedia, and recommended TV News Clips while visiting news websites.
- Site Map & Word Cloud — Present a sunburst diagram for the domain you are currently viewing, or create a Word Cloud from the link’s anchor text of the page you are on.






